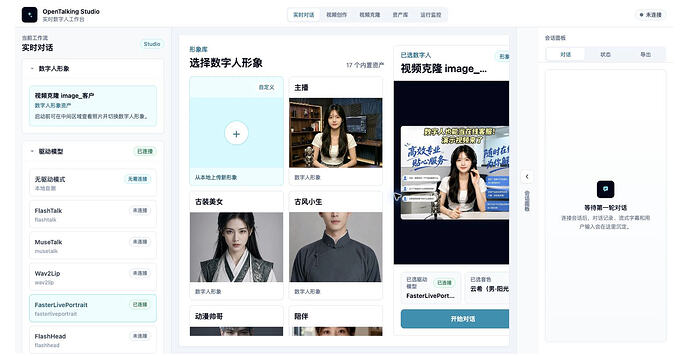
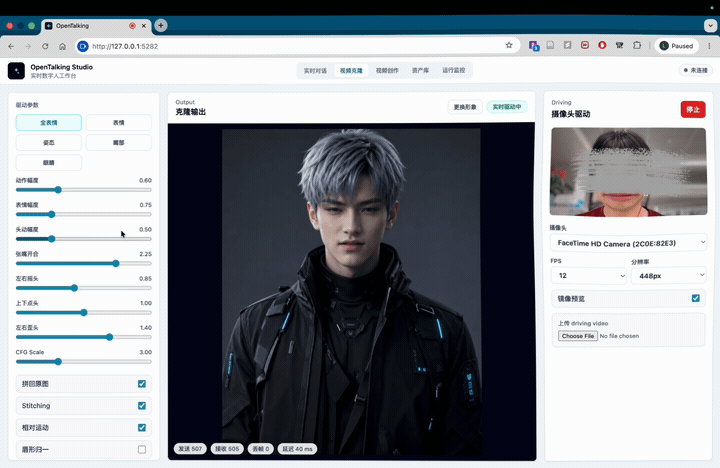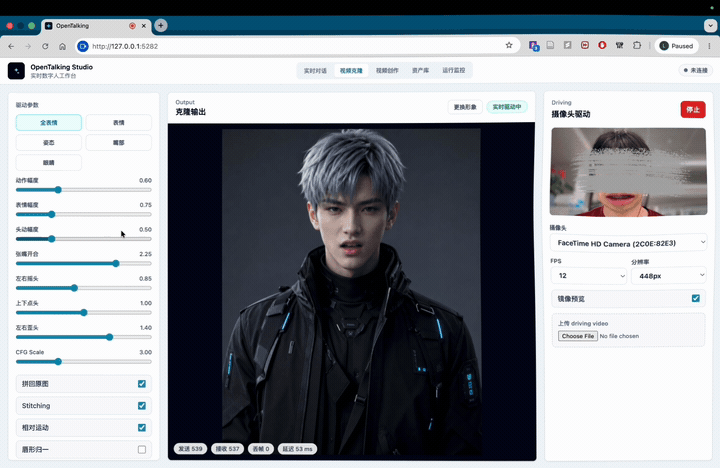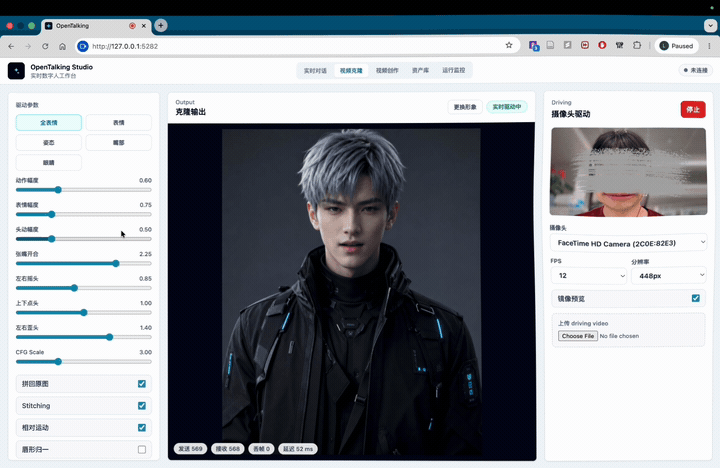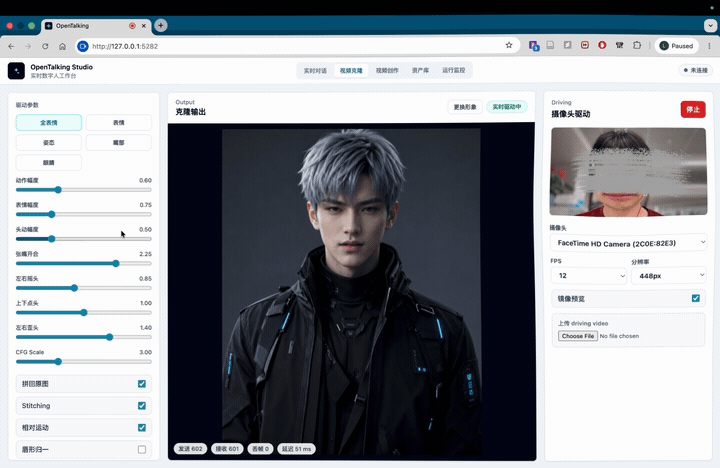
我花一个月做了个数字人开源项目Opentalking!支持自定义数字人完成实时对话、口播离线生成。欢迎各位大佬体验!
zyaire
2026-06-29 20:01
1
最新回复 (3)
-
 biau 06-29 20:021楼
biau 06-29 20:021楼 -
 huyl 06-29 20:062楼
huyl 06-29 20:062楼 -
 Hello 06-29 20:343楼
Hello 06-29 20:343楼
* 帖子来源Linux.do
附近帖子
- ↑【河北宽带问题】大家的电信千兆宽带都是怎么办的,河北有外网需求是电信还是联通?
- ↑不是,这对吗?D老师大家不是都说你便宜吗?
- ↑询问 cmlink UK 激活条件
- ↑生图站2api项目的一点“小问题”
- ↑[阿尔] 搓了一个占卜排盘的小工具
- 📍 我花一个月做了个数字人开源项目Opentalking!支持自定义数字人完成实时对话、口播离线生成。欢迎各位大佬体验!
- ↓AI小说 【申请AI小说板块】
- ↓giff gaff 保号时间求问,我是今天激活的,怎么知道下一次需要发短信动账的时间
- ↓做了好几年的go后端可以转ai agent吗
- ↓gpt系列的哪个模型写作能力较强
- ↓多数美国人会对着人工智能客服人员大喊大叫