deepseek花钱如流水,为啥你们说省钱?
Bensong
2026-06-30 16:23
1
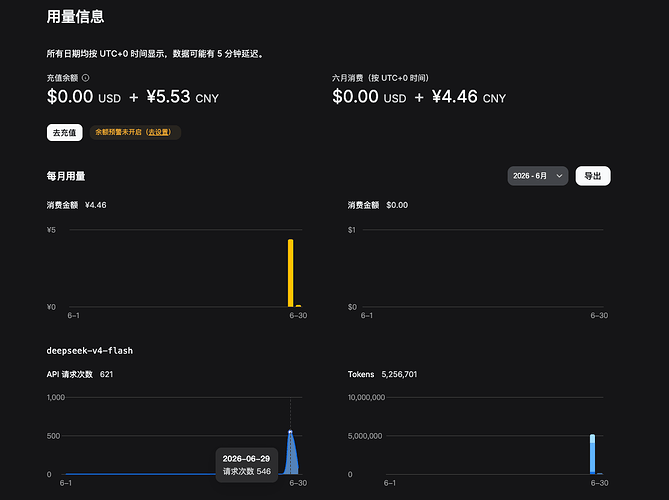
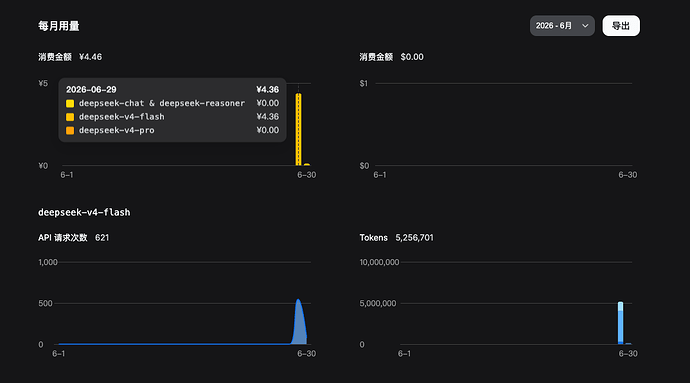
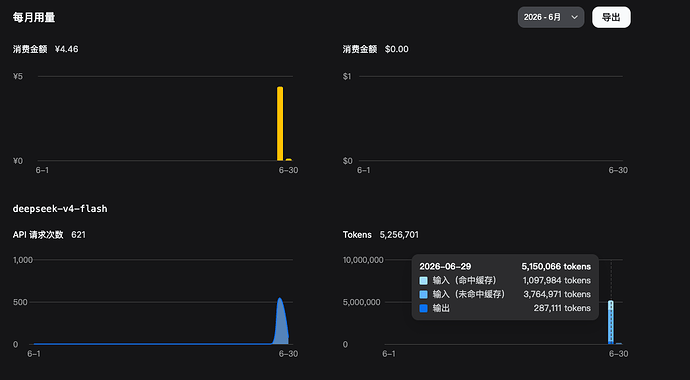
最新回复 (19)
-
 片刻月 06-30 16:241楼
片刻月 06-30 16:241楼 -
 Chisa 06-30 16:252楼
Chisa 06-30 16:252楼 -
 Bensong 楼主 06-30 16:253楼
Bensong 楼主 06-30 16:253楼 -
 别碰代码 06-30 16:254楼
别碰代码 06-30 16:254楼 -
 摩西 06-30 16:255楼
摩西 06-30 16:255楼 -
 a12908 06-30 16:266楼
a12908 06-30 16:266楼 -
片刻月 06-30 16:267楼
-
 蓝本西 06-30 16:268楼
蓝本西 06-30 16:268楼 -
 botbot 06-30 16:279楼
botbot 06-30 16:279楼 -
 24岁是白给 06-30 16:2710楼
24岁是白给 06-30 16:2710楼 -
 luoye2026 06-30 16:2711楼
luoye2026 06-30 16:2711楼 -
蓝本西 06-30 16:2712楼
-
 Yang 06-30 16:2713楼
Yang 06-30 16:2713楼 -
 ashu180 06-30 16:2814楼
ashu180 06-30 16:2814楼 -
 Nekopedia 06-30 16:2815楼
Nekopedia 06-30 16:2815楼 -
 这里404 06-30 16:2916楼
这里404 06-30 16:2916楼 -
 scp3500 06-30 16:2917楼
scp3500 06-30 16:2917楼 -
 guanyu 06-30 16:3018楼
guanyu 06-30 16:3018楼 -
 xiaofei xiao 06-30 16:3019楼
xiaofei xiao 06-30 16:3019楼
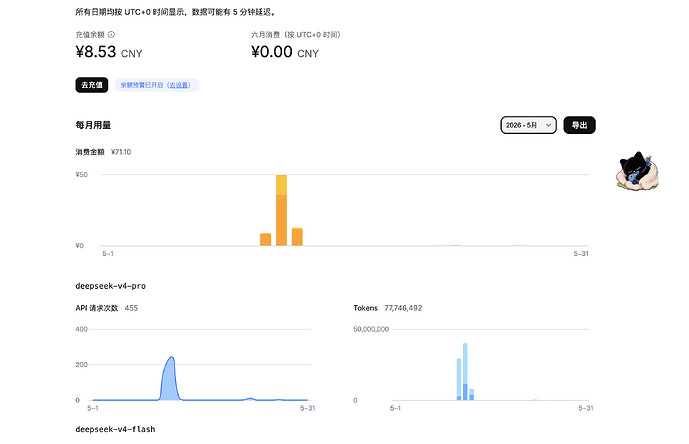
* 帖子来源Linux.do
附近帖子