前前言
考虑到本人写的东西可能会有逻辑不清楚,可读性不高的问题,所以使用了AI润色,产出如下AI润色版放在图片中。如果佬友愿意读AI润色版,可以直接看图片。

前言
梁圣每次发新模型,都会让我感觉到国模有质的飞跃。从Deepseek-v3.1 到现在Deepseek-v4-pro,全是性价比之选。前几天deepseek 发布了自家的加速大模型推理的架构 DSpark,作为一个老老实实的CS专业的本科生,我对LLM的了解仅限于道听途说,对大部分细节基本处于一知半解的情况。
最近突发奇想决定开始写点东西,防止自己的表达能力退化,正愁没有什么感兴趣的题材的时候,我看到了DSpark,刚好看到有佬友对DSpark会不会导致Deepseek降智有疑惑。于是,我决定通过对自己提问的方式来理解一下DSpark,在增强自己对LLM理解的同时,也能为各位感兴趣的佬友提供一些学习的思路。
以下内容属于个人思维链,可能存在谬误。
Attention是如何计算的?
对于一个简单输入X,线性映射计算三个维度相同的变量$Q$, K, V, Q = XW_{q}, K = XW_k, V = XW_v。在传统的decoder-only transformer语言模型中,输入向量维度是 [batch, heads, seq\_len, hidden\_dim],不考虑 KV-cache 的情况下,每次生成新的token,都需要对所有token做一次前向,计算所有token之间的attention map。
Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V
对于自回归式的语言模型,串行生成是不可避免的。目前的优化主要是针对单个token生成速度的优化,例如KV-cache等。而DSpark是为了连续多个token生成速度优化而做的改进,和DSpark 相关的优化方法叫做投机解码(Speculative decoding)。
投机解码是什么?
如果你经历过学生时代的刷题,那你有可能早就使用过一个方法论,就是先猜答案,然后验算。使用这样的计算方式, 如果猜对了答案,那么解题流程会比正常计算快很多,如果错了,便要换一个答案猜测或是直接走正常解题方式。
而在大模型推理中,如果我们先猜出后续的几个token,然后进行验算,如果验算的速度能显著快于从头生成,那么这就是一个极佳的推理加速方法。
事实上,在生成解码的过程中,除了计算时间以外,数据从HBM内存转移到GPU计算芯片的缓存中也消耗了大量的时间,如果直接有答案序列可以进行验证的话,那么就只需要搬运一次就可以进行多个token的推理(前提是连续n个token预测正确)。当然,如果预测正确率很低,就是浪费了一个猜测token序列的时间。
为什么投机解码会更快?
为什么验算的速度显著快于从头生成呢,是因为当前decoder-only transformer中使用的因果注意力,当输入序列变得更长的时候,前序几个变量的隐藏状态是不变的,因为第n个token的隐藏状态只取决于前n个token。于是,当预测出来的d个连续token被拼接到已经生成的n个token上之后,将这n+d个token一并输入到大模型中进行一次推理,即可得到整条n + d序列中每个token的隐藏状态。此时我们再从第n + 1 个token开始验证即可。而由于decoder-only transformer 中的主要计算集中attention的计算中,于是我们就通过一次前向,获得了x个正确token,其中x是d中经过大模型验证的前x个正确序列。
那么Speculative decoding 是如何完成token序列的预测呢?目前有多种方法,其核心想法都是使用一个相对较小的模型,以较小的推理成本去推理出连续多个token,供大模型确认。当我们失去了大模型的准确性的时候,我们换得了小模型的速度。然而只有速度,没有准确率是不行的,考虑极端情况,小模型输出的token几乎全不被大模型认可,这种情况下就是白白浪费了小模型推理的token以及大模型对于该批次所有额外token的计算,又快又快。 最初始的解决方式,是针对大模型的词表等架构单独训练一个独立同源的Transformer小模型,同时让小模型进行自回归生成,最终生成一批次的token。
然而这样的小模型自回归生成,显然还有优化的空间。有人通过深度蒸馏训练一个超浅层小模型,有人通过模型内置轻量预测头,复用大模型主干权重,还有人使用自回归隐状态预测头,复用大模型的LM head映射token。
2026年2月,Z lab本着优化到底的需求,提出了DFlash,使用轻量化block diffusion 替代传统自回归Draft小模型,这种架构可以一次性直接生成d个token,免去了自回归的串行要求。它在主模型prefill 阶段(生成第n个token的阶段)抽取多层中间隐状态,将投影压缩为target context feature,然后将特征注入每一层的KV Cache,让扩散模型拿到主模型的上下文,大幅度提高预测的准确率。而这个DFlash,就是DSpark的baseline。
DSpark 解决的问题是什么?
DSpark 做的事情,就是提高草稿模型输出token序列的准确性,没有改变投机解码的逻辑。所以验证DSpark会不会导致降智只需要验证投机解码会不会导致降智。
在DFlash的架构中,由于diffusion单次生成所有候选token的时候,每个位置无法看到其他位置的信息,容易出现语义冲突、后半段全错的情况,于是DSpark在并行的主干后加入了一层网络来进行生成token之间的交互。由于DFlash并行的优势仍然很重要,所以DSpark只是使用一层简单的马尔可夫时序头,以前一个token的表征来微调当前位置的概率分布,以极低的开销提升了长候选块的准确率。根据实验结果,DSpark 平均接受长度比DFlash高18%,在数学、代码等长文本场景优势最明显。
除此之外,传统的投机解码会将生成的d个token全都送往大模型验证,大量的尾部token白白占用了GPU的算力,在高并发的场景下拖累了表现。于是DSpark在输出对应token的同时还会输出该token的置信度(通过一个简单的MLP网络映射实现)。有了置信度,就可以选择是走完整验算还是只算高概率,灵活的调度方式使得模型能兼顾低负载的单用户加速和高并发的GPU利用率。
投机解码在数学上会不会影响最终生成结果?
如果你不想看推导过程,那么答案是:数学上不会。
设当前上下文固定,只需要证明单步下一个 token 的边缘分布不变,那么整序列分布自然就不会变。
定义:
- p(x): 目标大模型真实条件分布
- q(x): 草稿小模型的 draft 条件分布
- \hat{x} \sim q: 从草稿小模型采样到的候选 token
对于一个 token x 来说,接受概率定义为 a(\hat{x})=\min(1,\frac{p(\hat{x})}{q(\hat{x})}) ,x 被以 a(\hat{x}) 的概率接受,那么就是以 1-a(\hat{x}) 的概率拒绝。
如果这样进行采样的话,那么对所有的 token,总接受概率是 \sum_{x} q(x)a(x) = \sum_{x} \min(p(x), q(x)) .
总拒绝概率就是 p_{\text{fail}} = 1 -\sum_{x} \min(p(x),q(x)) =\sum_{x} p(x) - \sum_{x} \min(p(x), q(x))=\sum_{x} \max(0, p(x)-q(x)) .
在小模型采样被拒绝的情况下,也需要一个采样。那么最终的采样概率就是接受的情况下的采样概率加上拒绝的情况下的采样概率。
接受的情况下对于单个 token \hat{x}, p_{\text{ac}}(\hat{x}) = \min(1, \frac{p(\hat{x})}{q(\hat{x})}) * q(\hat{x})=\min(p(\hat{x}), q(\hat{x})) ;
拒绝的情况下,我们规定采样概率为 r(\hat{x}) = \frac{\max(0,p(\hat{x}) - q(\hat{x}))}{\sum_{x} \max(0, p(x)-q(x))},于是最终 p_{\text{fail}}(\hat{x}) = p_{\text{fail}} * r(\hat{x}) =\max(0,p(\hat{x}) - q(\hat{x})) .
总采样概率即 p_{\text{ac}}(\hat{x}) + p_{\text{fail}}(\hat{x}) = \min(p(\hat{x}), q(\hat{x})) + \max(0,p(\hat{x}) - q(\hat{x})).
接下来进行简单的分类讨论,当 p(\hat{x}) \ge q(\hat{x}),原概率为 q(\hat{x}) + p(\hat{x}) - q(\hat{x}) = p(\hat{x}),当 p(\hat{x}) < q(\hat{x}),原概率为 p(\hat{x})。
于是我们最终得到,这个采样概率在数值上就等于原大模型的真实条件分布。
既然我们证明了下一个token的分布是符合大模型真实分布的,由于大模型的自回归性质,每生成一个token都只和前n 个token的上下文有关,那么后续的所有token都是符合大模型真实分布的。于是我们就证明了投机解码不会改变大模型输出的分布。
投机解码在工程上会不会影响最终生成结果?
接下来就是大家最关心的事情了,实质上投机解码会不会导致大模型降智呢?答案是如果内部实现是完全的投机解码标准实现,那么其输出分布在统计学上是可以验证和原大模型一致的。
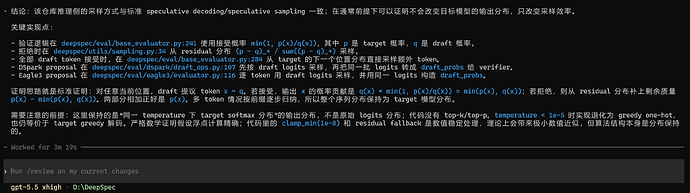
从DSpark的仓库代码来看,gpt-5.5 xhigh给出的结论是和标准实现一致,所以理论上不会有性能衰退。
参考链接
- DeepSpec GitHub 仓库
- DFlash: Block Diffusion for Flash Speculative Decoding
- Attention Is All You Need
- Fast Inference from Transformers via Speculative Decoding
 hwang 07-01 00:191楼
hwang 07-01 00:191楼 Suhuanzhen 07-01 00:192楼
Suhuanzhen 07-01 00:192楼 Smoaflie 07-01 00:313楼
Smoaflie 07-01 00:313楼 西西 07-01 00:464楼
西西 07-01 00:464楼