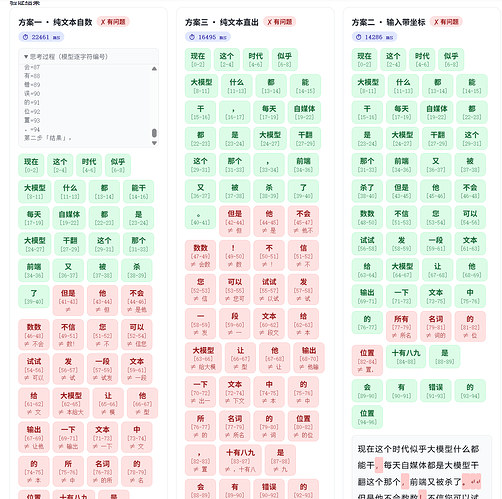
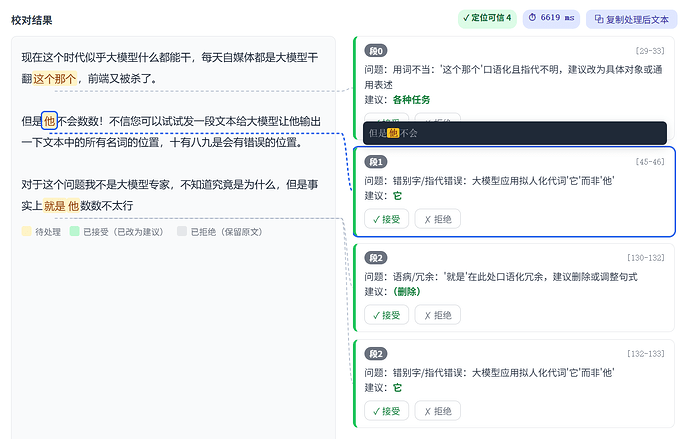
大模型不会数数!违反常识的问题
崮生
2026-06-30 21:15
1
最新回复 (9)
-
 亓水 06-30 21:181楼
亓水 06-30 21:181楼 -
 崮生 楼主 06-30 21:222楼
崮生 楼主 06-30 21:222楼 -
 yeluo001 06-30 21:343楼
yeluo001 06-30 21:343楼 -
 HeriX 06-30 21:364楼
HeriX 06-30 21:364楼 -
 Caphhh 06-30 23:125楼
Caphhh 06-30 23:125楼 -
 Wowfool 06-30 23:176楼
Wowfool 06-30 23:176楼 -
崮生 楼主 07-01 08:527楼
-
崮生 楼主 07-01 08:558楼
-
 招财进宝 07-01 09:019楼
招财进宝 07-01 09:019楼

* 帖子来源Linux.do
附近帖子
- ↑某品牌汽车销售公司直播造谣、抹黑**汽车,并剪辑成短视频在多平台发布,被行政处罚40万元
- ↑Claude Sonnet 5上线
- ↑[已解决]佬友们麻烦帮忙看看这个情况是不是中银狐木马了
- ↑A初登峰造极,Claude Code 内置中转站黑名单曝光,偷偷注入收集用户信息,随机修改用户 Prompt ?
- ↑fable5要解封了,我看说是明天上线。
- 📍 大模型不会数数!违反常识的问题
- ↓在这个日子any大善人大人会解封吗
- ↓不愧是 A/,中转名单都列出来了
- ↓[开源] yudao-document-free: yudao文档免费访问浏览器插件
- ↓A畜封号,遥测逆向分析,消息转载。
- ↓Claude近期封号潮原因似乎已经找到了