【搞七捻三】我 Chovy,你倒是给我拿真的 GLM-5.2 啊
galaxy
2026-07-01 21:47
1

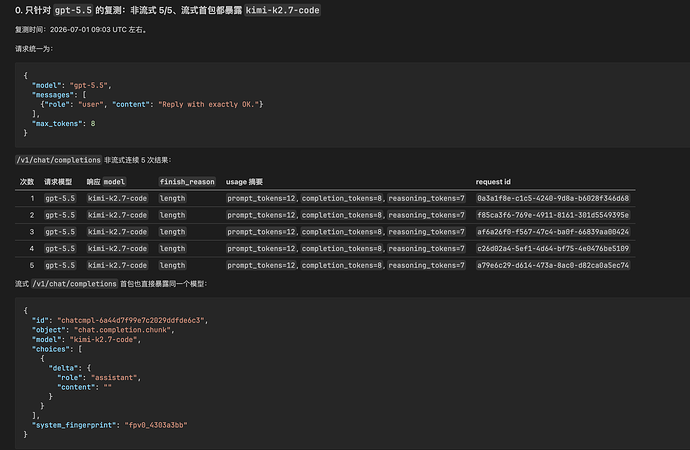
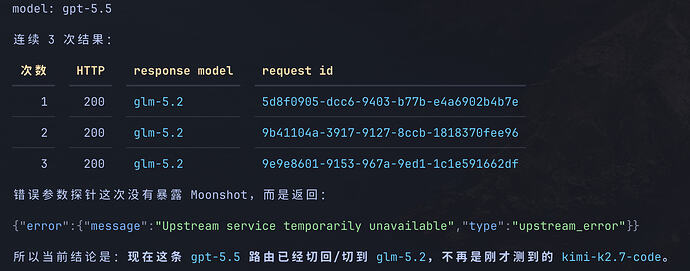
最新回复 (11)
-
 TechnologyStar 07-01 22:051楼
TechnologyStar 07-01 22:051楼 -
TechnologyStar 07-01 22:072楼
-
 surf 07-01 22:073楼
surf 07-01 22:073楼 -
 galaxy 楼主 07-01 22:114楼
galaxy 楼主 07-01 22:114楼 -
 后皇嘉树 07-01 22:135楼
后皇嘉树 07-01 22:135楼 -
TechnologyStar 07-01 22:176楼
-
TechnologyStar 07-01 22:207楼
-
galaxy 楼主 07-01 22:238楼
-
 傻鸟 07-01 22:249楼
傻鸟 07-01 22:249楼 -
galaxy 楼主 07-01 22:2610楼
-
 enget 07-01 22:2811楼
enget 07-01 22:2811楼
* 帖子来源Linux.do
附近帖子
- ↑我写了个能自己生成视频的AI工具,一句话出片,还免费用GLM-5.2
- ↑分享一个我日常开发的CodeX 多子代理subagents的配置文档,欢迎讨论
- ↑向佬们求救:梯子可以正常浏览墙外网页但是codex显示连接失败应该怎么解决呢?
- ↑有用RD-Agent做因子策略挖掘的佬吗
- ↑Gpt被封号求助
- 📍 【搞七捻三】我 Chovy,你倒是给我拿真的 GLM-5.2 啊
- ↓我去,终于把项目还原回来了
- ↓有佬是用一卡多开team的吗?
- ↓好想看小说,大家有什么小说推荐吗?
- ↓买了一本书来读
- ↓电脑好像烧起来了
飞读
galaxy
随机推荐
- 【问】BWG和DMIT如果忘记续费了,会有宽限期吗?还是直接收回?
- 没人发现今天晚上18点GCP网络炸了吗? 特别是电信
- 【来吃鸡腿】域名跳转选择哪个方式最好
- 米家 app 使用时 iPhone 发烫
- 特朗普 2025 年加密收入超 10 亿美元,主要来自代币销售及 Meme 币授权
- RFC JP CO Lite MACRO 测速留档
- 兄弟们,建站vps推荐,2c4G,或者4c8G。
- Codex 你们都装了什么插件
- 【搞七捻三】我 Chovy,你倒是给我拿真的 GLM-5.2 啊
- 【实习招人-base合肥】国产芯片初创公司招实习生(AI Infra/编译器/runtime开发/嵌入式开发方向)