本篇我们来简单梳理下 Claude Code 中 rules 的场景用法。
这里我从自己的日常团队开发协作角度来讲,因为我个人觉得这个规则一般情况下主要是在团队场景下使用的比较多吧。
比如我现在是公司某个项目组下面的一个小组长,手下加上我后端一共四个人。项目是团队一起开发的,我负责的内容里面包括代码评审。
之前我有说过,现在公司都开始推行 ai 辅助开发了,比如我们项目组要求我们团队统一用 claude code 来写代码。
本来我以为 ai 可以辅助大家一起进行项目提效,觉得会比传统开发团队协作的方式要好上很多,但用了一段时间之后,在进行 code review 的时候我还是总会发现了一堆问题:
比如同样是写一个查用户的函数,开发 A 同学提交的代码是这样的:
function getUserById(id: string) {
const user = await db.query('SELECT * FROM users WHERE id = ?', [id])
console.log('User fetched:', user)
return user
}
而开发 B 提交的代码则是这样写的:
async function get_user_by_id(userId: string) {
try {
const user = await db.findOne({ id: userId })
logger.info('Fetched user', { userId })
return user
} catch (error) {
logger.error('Failed to fetch user', { error, userId })
throw new ServiceError('User query failed', { cause: error })
}
}
同一个项目方法,两个人写出来的代码完全却不一样:
[!example]
比如方法名字,A使用camelCase,而B却用 snake_case风格
比如打印日志,A使用console.log,而B却用logger输出。
比如A并没处理错误,但B却用了完整的 try-catch
比如A查询使用 SELECT *,而B却明确指定字段来查询的。
每次 review 的时候我都要指出这些问题,然后再让对应的同学进行修正重新 commit。
而且实际情况是,ai 写的代码,全部靠人工来code review检查规范,根本检查不过来,总是会有遗漏出现,毕竟我也记不住每一条详细的代码执行规范。
有时候一天就要 review 十几个 PR,每个 PR 改了几十个文件。我要一个个看有没有用console.log、有没有处理错误、有没有用 SELECT*。看多了眼睛都花了,很容易就漏掉几个。
这里我也很无语,因为公司会定期扫描代码仓库查看代码的,写的太差或者有漏洞啥的会被问责的
而有的时候漏掉的恰好是关键问题,比如有个同事没处理异常,结果代码上线后遇到异常直接挂了。直到事后复盘才发现,code review 的时候我没发现这个问题
更加麻烦的是,随着 ai 大模型越来越厉害, 很多同事逐渐已经开始让 ai 全权接管代码了,ai 写完代码,本地测试没问题,直接就提交了。可能看都不看ai 写的代码质量。
所以如果没有明确的规范约束,每个人用 AI 写出来的代码质量就会导致参差不齐。
虽然产量是上去了,但质量下来了,这样反而增加了后期的维护负担。
以前古法编程的时候还可以让每个同学都过一遍自己写的代码,牢记项目开发规范。 但是现在是 AI 写代码了,如果没有一套明确的,而且AI 能理解并遵守的规范,代码质量根本没法保证。
特别是项目后期加入新人的时候,,不知道团队有什么规范。我给他发了几个文档链接,让他先看看。结果他看了两天还没看完,说文档太多了,不知道哪些是重点。后来没办法就让他直接用 Claude Code 开始写,结果写出来的代码更乱了。
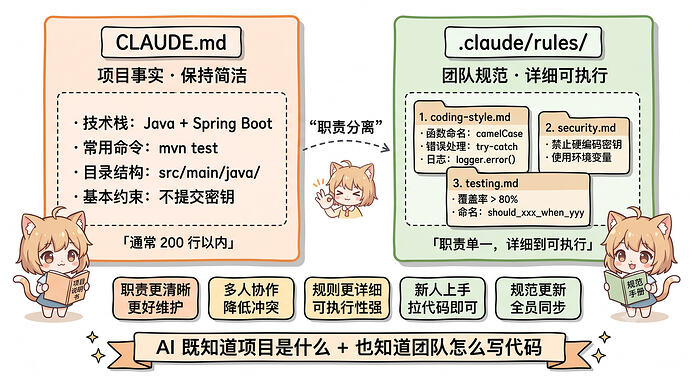
尽管我们项目有一直在维护的 CLAUDE.md文件,一开始我们的做法就是不断的复盘遇到问题,然后更新 CLAUDE.md文件内容。但写了之后发现,这条路其实是走不通的。

CLAUDE.md 的局限性:写得简单还是写得详细呢?
CLAUDE.md 确实可以提交到 git的,然后进行团队共享。但写的时候又会遇到一个两难的问题:
写得太简单的话,AI 不知道怎么做
比如我们在 CLAUDE.md 里面这样约束 ai:
# CLAUDE.md
- 不要用 console.log,统一用 logger
- 改接口要补测试
这种没有动作的规则要求,ai 再进行执行的时候可能知道有这个要求,但不知道具体怎么做:
[!example]
- logger 要怎么用呢?是
logger.info() 还是 logger.log()?参数是要怎么传?
- 测试要怎么补?是走单元测试还是集成测试?测试文件放哪里?命名规范是什么?
这种设计最终导致的结果就是每个人的理解都不一样,结果写出来的代码还是不统一。
写得太详细的话,又会遇到行数限制
如果我们想把所有详细规则都写进 CLAUDE.md的话,其实很快就会发现一个问题:
因为我们都知道官方一般建议 CLAUDE.md 保持简洁,目标控制在 200 行以内的,这里不是说超过 200 行就不能用,而是因为 CLAUDE.md 的内容会被加载到上下文里。写得越长,占用的上下文窗口就越多。
如果 CLAUDE.md 写了 500 行、1000 行,那么就会导致一些问题:
[!example]
- 上下文窗口被占满,留给实际对话和代码的空间变少
- ai注意力分散,规则太多,ai 其实更容易忽略后面的规则
- 加载变慢,结果就是每次启动 Claude Code 都要加载这么长的文件
所以一般情况下,我不建议把所有团队规范都塞进 CLAUDE.md的。CLAUDE.md 更适合精简规则、精准定位,把最关键的项目事实和入口信息讲清楚最好。
所以 CLAUDE.md 的定位应该是什么呢?
一般情况下,CLAUDE.md 是更适合写项目事实规则的,,可以按官方建议尽量保持在 200 行以内,比如这种类型的规则:
[!example]
- 技术栈是什么
- 常用命令是什么
- 目录结构是怎样的
- 有哪些基本约束
所以更加详细底线的团队规范不应该写在这里的,应该有专门的地方管理。
这就是 rules/ 目录存在的原因。
所以我们最终的目的就是如何通过 CLAUDE.md + rules/ 来建立我们的团队开发规范, CLAUDE.md主要负责项目事实,比如技术栈、常用命令、目录结构等。而 rules/主要负责详细规则,比如编码规范、安全底线、测试要求等。这样的话,CLAUDE.md 保持简洁,rules/ 写得详细。职责分离,各司其职。
我们这样做的好处可以有这些:
[!example]
- AI 既知道项目是什么样的(CLAUDE.md)
- 也知道团队怎么写代码(rules/)
- 规范更新后,提交到 git,全团队 pull 后可以拿到最新规则
- 新人拉代码就能拿到最新规范,不用再看一堆文档
rules/ 的价值:职责分离 + 详细到可执行
rules/ 同样是放在项目的 .claude/ 下面的,大概的结构是这样的:
my-project/
├─ CLAUDE.md # 项目基本信息
└─ .claude/
└─ rules/ # 团队开发规范
├─ security.md # 安全规范
├─ testing.md # 测试规范
└─ coding-style.md # 代码风格规范
所以首先我们第一步其实要做到的就是做好职责分离。所以按照我们团队协作的设计原则来看:
[!note]
- CLAUDE.md主要是负责项目是什么样的,也就是项目事实规则
- rules/主要记录我们的编码底线规范内容
按照这样来设计的话,CLAUDE.md 只需要保持简洁,只写项目基本信息。而rules/ 就可以写得详细一些,用来存放团队开发规范等规则。
比如我们在团队协作项目中可以这样来存放 rule 规则:
[!example]
rules/coding-style.md:代码风格约定(比如函数怎么命名、错误怎么处理、日志怎么打)
rules/api-design.md:接口设计规范(比如入参校验、响应格式、错误码定义)
rules/database.md:数据库操作规范(比如查询优化、事务处理、索引使用)
这样每个文件都专门管一类规则,这个具体怎么写呢,我们后面会详细讲解哈。
那么按照上面的我们这样做了职责分离之后,我们在团队协作开发中能解决哪些问题呢?
1. 职责更加清晰,更加好维护
比如我们的CLAUDE.md 只管项目事实,保持简洁。而详细的团队规范放在 rules/ 目录下,分文件管理。 这样各自职责明确,不会混在一起难以维护。
2. 多人协作维护降低冲突
比如我们在团队协作 rule 中可以这样来分工维护:
.claude/rules/
├─ coding-style.md # A 同学负责维护
├─ security.md # B 同学负责维护
└─ testing.md # C 同学负责维护
这样每个文件职责单一,多人可以同时维护不同的规则文件,提交的时候也不会冲突。
3. 规则可以写得更加详细
rules/ 里的规则其实可以写得足够的详细,这样就可以让 AI 能直接按规则执行。
比如我们可以在规则里面这样写:
[!example]
- 优先级(P0 必须遵守,P1 强烈建议)
- 正反示例(不要这样 / 要这样)
- 原因说明(为什么这样做)
类似于这种更加精细化的规则规范内容。
4. 新人上手会更快
如果团队项目中加入了新人,那么新人拉下代码就能看到完整的规范了,不用再去看一堆散落的文档,也不用问团队有什么规范文件什么的了。后面用 Claude Code 写代码时,ai至少能在上下文里看到这些规范,写出来的代码也会更接近团队要求了。
不过这里还是要注意一点,有的新人虽然拉了代码,但不一定知道要看 .claude/rules/的。
所以我们的做法是在团队 onboarding 文档里加一条:
[!note] 拉完代码后,先看 .claude/rules/ 目录,里面是团队的编码规范。 然后用 Claude Code 随便写点代码,观察 AI 是不是按团队规范来的。 如果发现 ai 写的代码不符合规范,说明 rules/ 可能没生效,再找我排查。
这样的话,新人至少知道这个目录的存在,也知道怎么验证规则有没有生效。
5. 规范更新则全员同步
因为这个 rule 规范是需要随着项目的迭代不断的去优化更新的,当规范更新后,我们可以提交到 git仓库,然后让全员 pull 代码,这样新会话或者重新加载后,就能拿到最新规则。
不过这里不要理解成规则一改,所有人正在运行的 claude code 会话就能立刻生效哦,比较重要的规则变更,还是建议在群里或者团队例会上同步一下,提醒大家 pull 最新代码并重新开启会话。这样既能利用 git 做统一分发,也不会因为有人还在旧上下文里作而漏掉关键变更了。
rules/ 的加载方式:全局规则和路径规则
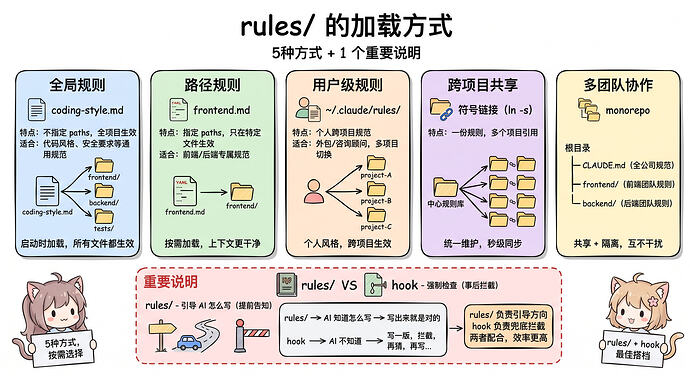
然后我们再来了解一下 rules 的加载方式,rules/ 目录下的规则有三类常见使用方式:无条件规则、路径范围规则、用户级规则这些。
先讲第一种:全局规则
最常见的写法,规则文件里不指定 paths,直接写规则内容就行,比如这样的:
# 代码风格约定
- 函数命名用 camelCase
- 错误处理必须用 try-catch
- 日志统一用 logger,不要用 console.log
我们设定了这种规则后,claude code 在启动的时候就会加载到上下文里。不管我们在处理哪个文件,这些规则都会生效的。这种比较适合放全项目通用的规范,比如代码风格、安全要求这些。
第二种:路径规则(path-scoped rules)
路径规则是 rules/ 里一个比较重要的特性,可能很多人还没用过这个。
这个意思其实就是我们可以指定这条规则只在处理某些文件时才生效。
那这个是要怎么指定呢?比如我们可以在规则文件的开头加一段 YAML 格式的 paths 声明(ai 整理的代码也不行,擦截图了):

我们需要注意最上面的那段 --- 包裹的内容哈,也就是 paths 声明。
它会告诉 claude code这条规则只在处理 src/api/ 目录下的 .ts 和 .tsx文件时才加载,至于其他目录的文件呢,这条规则就不会加载,也不会占用上下文空间的。
还有一点我需要解释下,那就是什么有时候我们需要路径规则呢?
这里我举个例子,比如我们团队的项目是前后端分离的,目录结构大概是这样的:
my-project/
├── frontend/ # React 前端
├── backend/ # Node.js 后端
└── .claude/
└── rules/
├── coding-style.md # 全局代码风格
├── frontend.md # 前端专属规范
└── backend.md # 后端专属规范
如果我们把所有规则都在启动时加载,问题就来了,比如前端规则 + 后端规则 + 测试规则全都加载,上下文窗口一下子就被占满了。 而且处理前端代码的时候,ai还要记住后端的规范,容易搞混,最主要的是规则越多,ai 注意力越分散,遵守的效果反而变差。
所以我们需要采用路径规则,这样处理之后,我们就可以处理 frontend/ 下的文件,只加载前端规则,而处理 backend/ 下的文件,只加载后端规则,这样的话上下文也更加干净,ai 执行起来也更加专注。
路径规则里的匹配模式也简单举例一下
paths 字段支持 glob 模式,常用的就这几个(ai 整理的已截图展示):

我们也可以指定多个模式,还能用花括号匹配多种扩展名比如这样的:
---
paths:
- "src/**/*.{ts,tsx}"
- "lib/**/*.ts"
- "tests/**/*.test.ts"
---
第三种:用户级规则(个人偏好)
除了项目级的 .claude/rules/,其实还有用户级的 ~/.claude/rules/,这是我们个人的跨项目规范。
比如我们个人有这些习惯:
[!example]
- 写日志时永远带上时间戳
- 错误处理必须记录堆栈
- 测试用例命名用
should_xxx_when_yyy 格式
那这些规则我们就可以放在这里:
~/.claude/rules/
├── preferences.md # 个人编码偏好
└── workflows.md # 个人首选工作流
这样无论我们切到哪个项目下面,claude code 都会去加载我们的个人规范的哈。
那这种一般适合什么场景呢?
比如我们需要在多个项目间进行切换,又想保持一致的个人风格。或者团队规范之外呢,我们还有额外的个人习惯等等,
再比如是外包或者咨询顾问这种,经常接触不同客户的项目的,这时候用户级规则就很有用了。
不过这里还是要注意一点,用户级规则和项目级规则会同时生效的,如果有冲突的话,项目级优先级更高哈,因为加载顺序靠后的。
跨项目共享规则,用符号链接
如果我们负责多个项目的话,团队还有统一的编码规范,那其实我们就可以用符号链接避免重复维护了。
这里举个例子,比如公司有 10 个微服务项目,都用 Java + Spring Boot,编码规范完全一样。
这时候我们可以维护一份中心化的规则,各项目通过符号链接引用:
# 在公司内网 Git 仓库维护规则
~/company-standards/
├── java-style.md
├── api-design.md
└── security.md
# 各项目通过符号链接引用
cd my-project/.claude/rules/
ln -s ~/company-standards/java-style.md java-style.md
ln -s ~/company-standards/api-design.md api-design.md
这样做的好处是:
[!example]
- 规则只需要维护一份,10 个项目同步更新。
- 新项目直接 ln -s,秒级接入
- 可以配合 Git submodule 或公司内网 NFS 共享
不过这里要注意一点,符号链接在 windows 上需要管理员权限,如果团队有 windows 用户的话,建议改用 git submodule。
多团队协作的规则管理
如果是 monorepo,多个团队在同一个仓库协作的话,这里要稍微注意一下哈, 不要简单理解成每个子目录下面放一个 .claude/rules/,claude code 就一定会按团队自动分层加载。这种一般我们有两种做法。
第一种:用子目录 CLAUDE.md 区分团队上下文
比如目录结构我们可以这样设定
monorepo/
├── CLAUDE.md # 全公司通用规范
├── frontend/
│ └── CLAUDE.md # 前端团队特有规范
└── backend/
└── CLAUDE.md # 后端团队特有规范
这种方式适合把每个团队的项目事实,常用命令还有目录说明放到各自目录下面。 比如前端同学在 frontend/ 目录下工作时,claude code 就更容易拿到前端相关的上下文, 后端同学在 backend/ 目录下工作时,就更容易拿到后端相关的上下文。
第二种:把团队规范集中放在根目录 .claude/rules/下面,然后再用 paths 控制适用范围
如果是更细的编码规范,我更建议放在仓库根目录的 .claude/rules/ 里,然后用路径规则来区分前后端:
monorepo/
├── CLAUDE.md
├── frontend/
├── backend/
└── .claude/
└── rules/
├── frontend.md
└── backend.md
比如 frontend.md 我们就可以这样写:
---
paths:
- "frontend/**/*.{ts,tsx}"
---
# 前端开发规范
- React 组件用 PascalCase
- 状态管理优先使用项目现有方案
- 修改组件时同步补充必要测试
backend.md 我们可以这样写:
---
paths:
- "backend/**/*.java"
---
# 后端开发规范
- Controller 不写业务逻辑
- 数据库变更必须走 migration
- 对外接口必须做入参校验
我们这样组织的好处是根目录 CLAUDE.md 负责全仓库共识,而子目录 CLAUDE.md 负责团队事实, 而 .claude/rules/ 负责可执行的编码规范。前端规则只在处理前端文件时触发,后端规则只在处理后端文件时触发,规则边界会更清楚。
这里有个重要的点要说明一下
CLAUDE.md 和 rules/ 都是在引导 ai 的行为,不是强制执行哦,也就是说它们都是作为上下文加载到ai的,ai 只会尽量去遵守,但不保证 100% 执行。毕竟我之前也解释过,大模型是有自己的判断的,有时候它认为某条规则在当前场景下不适用,那就会跳过。
举个简单的例子来说,比如我们在 rules/coding-style.md 里写了函数命名用 camelCase,但我们在对话里临时说这次用 snake_case,ai也会听我们的哈。
那这样的话可能会有同学不理解, 既然不保证 100% 执行,那为什么我们不全用 hook 来强制约束ai 执行规范呢?
所以这里我也解释一下,因为 hook 只能检查结果,却不能教 ai 怎么写的呀。
还是举个例子来说,比如我们团队要求错误处理要这样写:
# rules/coding-style.md
- 错误处理用 try-catch
- 错误日志用 logger.error()
- 错误对象要带上下文信息,比如 userId、requestId
然后等 ai看到这些规则之后,再写代码的时候就知道要怎么做了,比如先加 try-catch,再用 logger.error() 记录,最后把 userId 这些上下文带上。这样写出来的代码基本就是对的。
但是如果我们只用 hook 强制检查的话:
那我们只能在 ai 写完代码后去检查,发现没用 try-catch 就拦截掉。
而且ai不知道我们具体要什么,只能猜是不是要加 try-catch?是不是要用 logger?要带哪些上下文信息?然后写一版,被拦截了。再猜,再写,又被拦截… 一直这样反复修改。效率也非常低的。
所以一般合理的分工还是这样比较好一点:
[!tip]
- rules/:负责提前告诉ai应该怎么写,主要是引导方向
- hook:负责事后检查有没有做那些绝对不能做的事,主要是兜底拦截
rules/ 让 ai尽量往对的方向写,大部分情况下就能写对。而hook 只拦截那些必须拦截的情况,比如提交了 API 密钥、跳过了 lint 检查等,这样两者配合,效率更高。
关于 hook 的详细用法,我在之前的Claude Code Hook,当 CLAUDE.md 规则不生效时,我们还需要强制拦截机制里分享过,感兴趣的佬可以看看哈
关于团队规则的持续演进
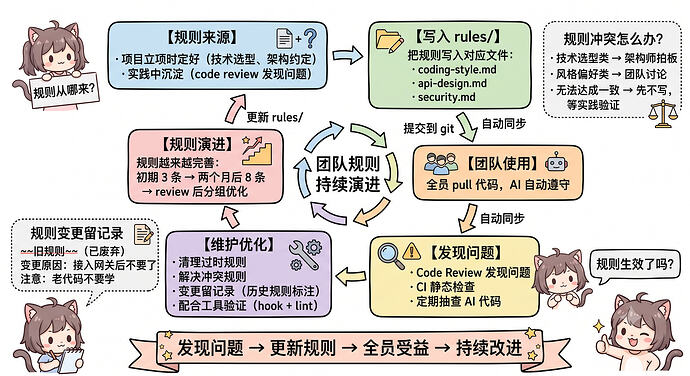
前面我们讲了 rules/ 是什么、以及是怎么加载的,那么这些规则从哪里来呢?
这里我还是分享下我项目的来源,主要有两个。
第一种是项目开始时就定好的规则
这些规则属于技术选型和架构约定,项目立项的时候基本就定下来了。
比如我们团队有个这样的项目是这样设置风格的:
[!example]
- 响应格式统一用json 形式
- 函数命名用 camelCase 小驼峰
- 日志统一用 slf4j,不用 System.out
- 错误处理统一用 try-catch
类似于这种规则在技术方案评审的时候就定了,直接写进 rules/coding-style.md 和 rules/api-design.md就行。
第二种是实践过程中沉淀的规则
一般情况下,这种规则都是我们在实际开发、code review 的过程中,逐渐发现问题、 然后再总结提取出来的。
还是举个例子,比如项目刚开始的时候,我们在CLAUDE.md 里只写了一句:接口要统一返回格式。
结果开发过程中,开发 A 写了个接口,没做入参校验,前端传了个空字符串,后端直接报 500 了。
我在 code review 的时候就让他加上校验。
但是过了一段时间,开发 B 又犯了同样的错误。
针对这种反复出现的问题, 于是我在 rules/api-design.md 里加了一段:
## 入参校验
- 所有接口必须校验入参
- 必填参数不能为空
- 数值类型要校验范围
- 字符串要校验长度
不要这样:
public User getUser(String userId) {
return userService.findById(userId);
}
要这样:
public User getUser(@NotBlank String userId) {
if (userId == null || userId.trim().isEmpty()) {
throw new BadRequestException("userId 不能为空");
}
return userService.findById(userId);
}
这样写进去之后,这类问题就少多了。
还有一点,规则是要定期清理的
在项目日常迭代中,当我们把规则写进去之后,还要定期看看有没有过时的。
比如我们团队现在是每个大版本就 review 一次 rules/。
清理掉过时的规则
比如之前我们要求所有接口响应都要包装成 { code, data, message } 格式。
但是后面我们接入了公司统一的网关,网关会自动包装,这条规则就多余了。
如果不删掉的话,ai还会按这个规则写,结果就是包装了两层。
解决冲突的规则
有时候不同的 rules/ 文件会有冲突的。
比如 coding-style.md 里说函数命名用 camelCase,但后来有人在 database.md 里加了一条"数据库字段用 snake_case"。
ai看到这两条, 是有可能会搞混的。所以定期 review 的时候,我们会把这些冲突找出来,明确适用范围。
如果遇到规则冲突时怎么办呢
在我们团队协作中,不同角色对规则的理解可能是不一样的。
比如我们之前就遇到过,前端同学希望接口响应扁平化({data: []}),后端同学希望嵌套便于扩展({data: {list: [], meta:{}}})。
两边其实各有道理的,但如果写进 rules/ 就冲突了。
所以一般情况下我们的做法是这样的:
[!example]
如果是技术选型类的规则,那就是后端组长拍板,写进 rules/ 就是最终决定
如果是风格偏好类的规则,那就先在团队会上讨论,然后达成一致再写进去
如果短期无法达成一致,就先不写进 rules/,保持现状,等实践中看哪种更合适
总之肯定不能出现两个组长各写各的, 这样ai 看到两条相反的规则,不知道听谁的这种情况。
最后规则要配合工具验证
我上面提到过,rules/ 只是引导ai 去怎么写,但不保证百分百执行的。所以我们还要去配合其他工具来验证。
hook 兜底关键规则
比如我们是不允许提交api 密钥到仓库的,这种规则必须用 hook 强制检查。
所以我们在 PreToolUse hook 里加了检查,如果代码里包含 API_KEY =、password = 这种明文敏感信息,就直接拦截(这里只是举个简单的例子 实际上不会这么简单草率的哈)。
lint 和 test 验证代码质量
虽然rules/ 里写了代码风格要求,但最终我们还是要靠 checkstyle 或 lint 来检查。
比如我们在CI里跑检查,不通过就不让合并。
code review 处理判断型问题
最后就是还有一些规则是判断型的,比如这个功能要不要加缓存、这个接口设计是否合理等等。
往往这种规则问题 ai 是判断不了的,所以最终还是要靠人来 review。
那怎么衡量规则是否生效呢
作为组长,我们需要知道团队规范是不是真的在起作用。
一般情况下我们的做法是这样的:
1.如果 code review 的时候统计下问题类型,比如每此迭代更新的时候统计 CR 中发现的问题:命名不规范、缺少错误处理、日志打印不对等,如果某类问题反复出现,说明对应的规则没生效,就需要改进。
2.CI 里跑下静态检查,比如有些项目可能会用 checkstyle、eslint 等工具检查代码风格,统计每周的违规数量,看趋势是上升还是下降。
3.就是定期抽查 ai生成的代码了,比如每个月随机抽查几个 PR,看 ai 写的代码是否符合团队规范,如果发现 ai 经常不遵守某条规则,说明这条规则写得不够清楚。
有了这些数据,我们才能客观评估规则的效果,而不是不清不楚到底规则生效了没有。
一个rule的演进过程
举个例子,比如我们团队的 rules/api-design.md 就是这样一点点完善起来的。
项目初期的时候(架构规则,3 条):
然后大概两个月后(比如发现了新问题,又加了 5 条):

大版本 review 后(清理优化,分组更清晰):

这样规则从 3 条到 8 条,再优化成分组结构。这个过程就是在实践中不断发现问题、沉淀规则、清理冗余的。
举个完整例字:我项目的某个部分配置
前面我讲了这么多,然后我把我们团队之前的项目的配置简单整理一下,给大家一个可以直接参考的完整例子。
比如我们是一个后端团队,是用 Java + Spring Boot的,大概后端四个人。目录结构大概是这样的:
my-project/
├─ CLAUDE.md
└─ .claude/
└─ rules/
├─ coding-style.md # 代码风格(全局)
├─ api-design.md # 接口规范(全局)
├─ database.md # 数据库规范(全局)
└─ controller.md # Controller 层规范(路径规则)
然后我们下面一个一个看吧。
CLAUDE.md:只放项目事实
这个我们上面也说了,CLAUDE.md 要保持简洁,只写项目基本信息,大概控制在 200 行以内:
# 订单服务
## 技术栈
- 语言:Java 17
- 框架:Spring Boot 3.x
- 数据库:PostgreSQL
- 缓存:Redis
- 构建工具:Maven
## 常用命令
- 启动服务:`mvn spring-boot:run`
- 运行测试:`mvn test`
- 打包:`mvn clean package`
- 代码检查:`mvn checkstyle:check`
## 目录结构
- `src/main/java/com/xxx/controller`:接口层
- `src/main/java/com/xxx/service`:业务层
- `src/main/java/com/xxx/mapper`:数据层
- `src/main/resources`:配置文件
## 基本约束
- 数据库表结构改动走 Flyway migration,不要手动改库
- 不要提交本地配置文件,比如 application-local.yml
- 涉及支付、权限的改动,先找我评审
可以看到这里放的都是项目事实,比如用什么技术、怎么启动、目录怎么分、有哪些红线。
rules/coding-style.md:代码风格
这个是全局规则,没有 paths,启动时就加载:
# 代码风格约定
## 命名
- 类名用 PascalCase
- 方法名、变量名用 camelCase
- 常量用 UPPER_SNAKE_CASE
## 日志
- 统一用 slf4j,不要用 System.out
- 关键操作要打日志,带上 traceId
## 错误处理
- 所有对外方法要处理异常
- 错误日志用 log.error(),带上下文
- 不要吞异常,也不要直接打印堆栈
不要这样:
try {
doSomething();
} catch (Exception e) {
e.printStackTrace();
}
要这样:
try {
doSomething();
} catch (Exception e) {
log.error("处理订单失败, orderId={}", orderId, e);
throw new ServiceException("订单处理失败", e);
}
rules/api-design.md:接口规范
这个也是全局规则:
# API 设计规范
## 接口命名
- 接口风格:RESTful
- 路径用小写,资源用复数,如 /orders、/users
- 用 HTTP 方法表达操作
## 请求规范
- 所有接口必须校验入参
- 分页参数统一用 page 和 pageSize
- 查询条件用 query 参数
## 响应规范
- 统一返回格式:{ code, data, message }
- 错误码遵循 HTTP 标准
- 列表接口必须返回总数 total
rules/database.md:数据库规范
这个同样是全局规则:
# 数据库操作规范
## 查询
- 明确指定字段,避免 SELECT *
- 分页查询单次最多 100 条
- 复杂查询要确认走了索引
## 写入
- 批量操作用 batch,不要循环单条插入
- 涉及多表写入要加事务
- 用逻辑删除(deleted_at),不做物理删除
## 事务
- 事务方法用 @Transactional
- 注意同类内部方法调用会让 @Transactional 失效
- 事务里不要放远程调用、发消息这类耗时操作
不过这里的第二条我要多说一句。@Transactional 在同类内部自调用会失效,这是 Java 里很常见的坑。我们之前有个同事就踩过,ai也犯过同样的错误,所以专门写进规则里提醒。
rules/controller.md:只在改接口层时加载
这个用了路径规则,只有处理 controller 目录下的文件时才加载:
---
paths:
- "**/controller/**/*.java"
---
# Controller 层规范
- Controller 只做参数校验和调用 service,不写业务逻辑
- 入参用 @Valid 校验
- 返回值统一用 Result 包装
- 不要在 Controller 里直接操作数据库
所以为什么这条要用路径规则呢?
因为这条规则只在写接口层的时候有用。我们处理 service 层、数据层的代码时,根本不需要它。
我们用路径规则圈定范围,处理别的目录时它就不加载,省下来的上下文空间就更多了。
整体效果
我们配好这一套之后,我们团队的协作明显顺畅了很多。
如果有新人进来的话,直接拉个代码,claude code 就自动知道我们的规范了,写出来的代码风格基本统一。
而我们code review 的时候,那些低级的格式问题、命名问题几乎不用再提了,我可以把精力放在业务逻辑和设计上。
所以类似这套配置也是我们用了几个月,一点点补出来的。一开始只有寥寥几条,遇到问题就补一条,慢慢才长成现在这样。
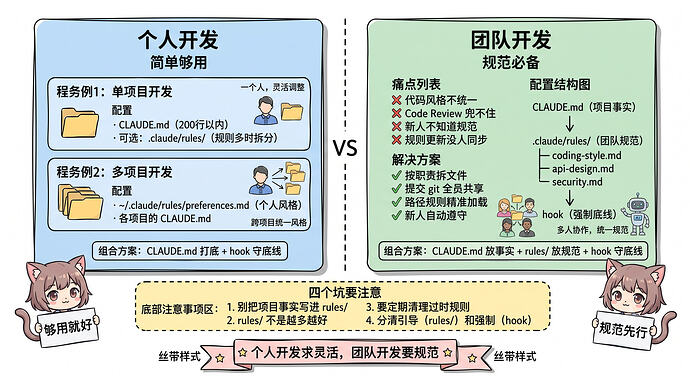
最后一点:个人开发和团队开发,用法不一样的
写到这里,我们把 rules/ 这套东西基本讲完了。最后我想从个人开发和团队开发两个角度,帮大家理一下到底该怎么用。
如果是个人开发,其实用不太上 rules/
如果只是我们自己一个人写项目,其实rules/ 的价值不大。
个人觉得一个 CLAUDE.md 基本就够了。项目事实、常用命令、几条约束,全写在里面,200 行以内,加载起来也不费上下文。
毕竟自己的规范自己也清楚,哪条规则临时想改,直接对话里说一句就行了。也不会存在多人协作、新人对齐这些问题的。
真要是有些必须强制的底线的话,比如别提交密钥,感觉直接配个 hook 就完全足够了。
所以个人开发的组合很简单的,我建议CLAUDE.md 打底,关键处加 hook就行。
如果是团队开发,rules/ 才真正有价值的
一旦是多个人协作的话,情况就不一样了。
我们前面讲的那些问题就全冒出来了,比如每个人代码风格不一样、code review 兜不住、新人也不知道规范、规则更新没人同步等等问题。
所以这时候光靠 CLAUDE.md 就不太够了。规则一多,CLAUDE.md 就撑爆了 200 行;规则一细,又全挤在一个文件里没法维护了。
所以说rules/ 的价值就在这里:
[!example]
- 按职责拆成多个文件,谁负责哪块清清楚楚
- 提交进 git,全团队一份,改了一起改
- 用路径规则,让规则只在对应的目录生效,上下文更干净
- 新人拉个代码,AI 就自动按团队规范写了
所以团队开发的组合是CLAUDE.md 放事实规则,而rules/ 放规范,hook 就负责守底线。
我们使用的时候,还有几个坑也要注意下
第一,别把项目事实写进 rules/来
像技术栈、启动命令这种,是项目事实规则,应该放 CLAUDE.md里面。rules/ 只放怎么写代码的规范。这两个别混哈。
第二,rules/ 不是写得越多越好的哈
上面我也说了,规则堆太多,ai 反而记不住,注意力会分散。只写那些 ai 自己推断不出来、又反复出错的规则。能靠 lint、hook 强制的,就别在 rules/ 里啰嗦。
第三,要定期清理
规则是会过时的,也会互相冲突。每隔一段时间翻一下记录,把没用的删掉,把冲突的规则理清楚一下。不然 ai 拿着一堆矛盾的规则,反而更容易出错。
第四,分清楚哪些是引导,哪些是强制行为
CLAUDE.md 和 rules/ 都是引导 ai 的,不能保证百分百执行的。真正不能碰的底线,还得靠 hook 拦。千万不要指望写进 rules/ 就万事大吉了哈。
最后呢,虽然我们大多数时候直接用 claude code 对话开发其实已经足够了,让ai 直接执行就能把事情做完。但 claude code 提供了很多机制来辅助我们做得更好。
比如这篇讲的 rules/,比如上一篇讲的 hook,它们解决的都是对话模式里不太好处理的问题:
[!example]
- CLAUDE.md 让 AI 知道这是个什么项目
- rules/ 让团队规范能模块化管理,不用每次对话都重复
- hook 让必须强制执行的底线能真正拦住
特别是我们是团队协作的时候,大家都用 ai 的,其实是很头大的一件事。毕竟每个人写法不一样,质量参差不齐。
特别是作为组长或者带团队的人,我们要做的就是既让团队能用 AI 提效,又能保证代码质量不掉下来。
虽然这些机制不是必须的,但知道它们是干嘛的、什么时候该用,遇到问题时就能拿出来解决。
后面再写另外一个了了了。
参考/学习文档:
 kailvin 07-01 23:011楼
kailvin 07-01 23:011楼 洛卡卡了 楼主 07-01 23:022楼
洛卡卡了 楼主 07-01 23:022楼 刺猬 07-01 23:533楼
刺猬 07-01 23:533楼 jqtmviyu 07-01 23:574楼
jqtmviyu 07-01 23:574楼