本帖使用社区开源推广,符合推广要求。我申明并遵循社区要求的以下内容:
我的帖子已经打上 开源推广 标签: 是我的开源项目完整开源,无未开源部分: 是我的开源项目已链接认可 LINUX DO 社区: 是我帖子内的项目介绍,AI生成、润色内容部分已截图发出: 是以上选择我承诺是永久有效的,接受社区和佬友监督: 是以下为项目介绍正文内容,AI生成、润色内容已使用截图方式发出
佬友们好,这是我编写的一个完全 harness-engineering 驱动落地的复杂工程项目 Fleur。
GitHub - WackyGem/Fleur: Fleur 是一个由 harness-engineering 驱动 100% AI Coding...
Fleur 是一个由 harness-engineering 驱动 100% AI Coding 的面向沪深A股投研平台,功能覆盖行情与财务数据采集、技术指标计算、规则选股、策略回测、及组合运行监控。
Fleur 的工程目标
验证完全 harness-engineering 驱动的复杂度及落地可行性; 一个自动调度采集行情数据和财务会计报表的作业平台; 一个集成了数据清洗、模型转换、数据加工和指标计算能力的数据仓库; 一个灵活构建指标选股、策略回测、策略订阅和组合业绩评价的投研应用工作台。
应用功能演示
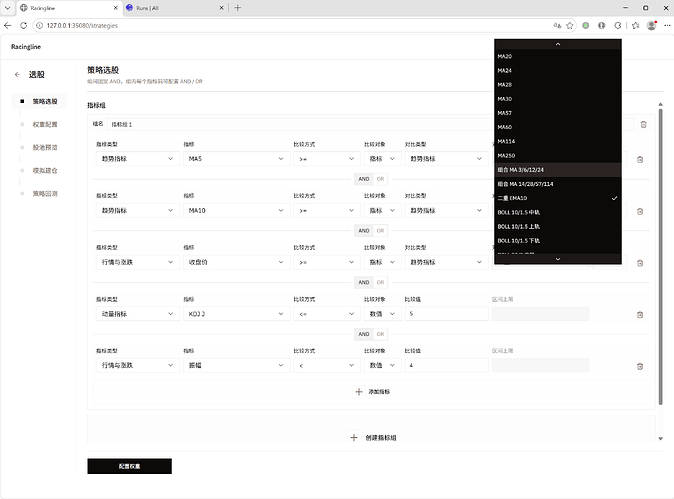
step1. 构建股票池的筛选规则, 目前项目支持行情涨跌(高开低收、涨跌幅、PE、PB、ROE、ROA)动量指标(KDJ、RSI、MACD)、趋势均线(MA、EMA、BOLL)、量能指标、价格结构(连阳连阴、前低 / 次低结构、N字结构)等常见指标的组合筛选, 基本覆盖了常用的选股规则。 可以通过图形化页面配置筛选规则构建股票池。
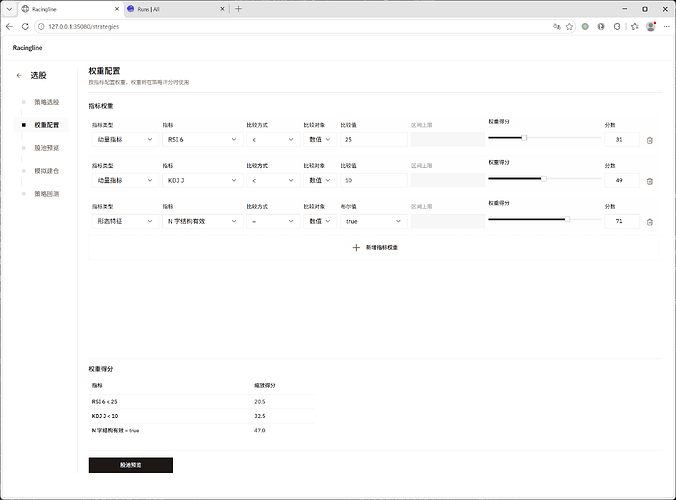
step2. 权重配置, 这一步是对股票池内的个股评分排序,获得信号强度和优先级。
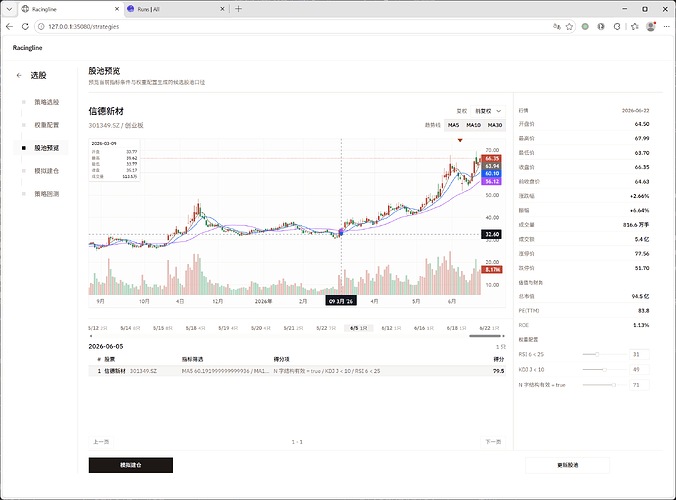
step3. 股池预览, 对指标选股策略中筛选的股票进行行情走势的预览,观察筛选出的个股的走势图是否符合自己的技术面预期,可以重新调整权重配置调整股池内的信号强度。
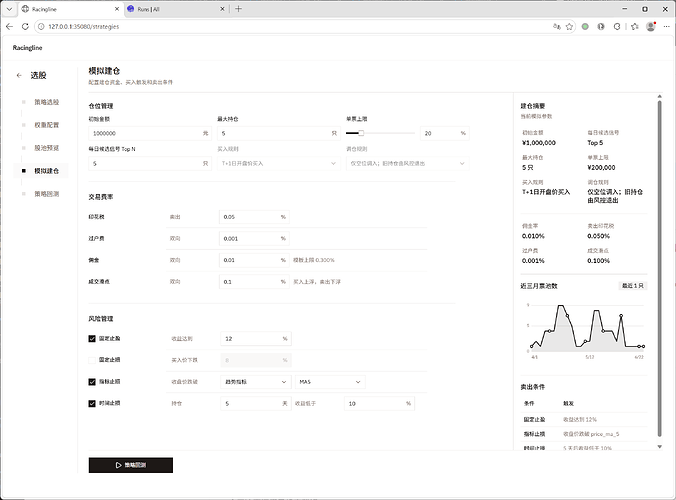
step4. 模拟仓位和风控配置。 这一步是配置模拟仓的仓位和建仓的买入卖出规则。目前只实现了最基本的T日选股 T+1日按照开盘价和交易滑点的组合买入, 然后根据设定的风控规则卖出。
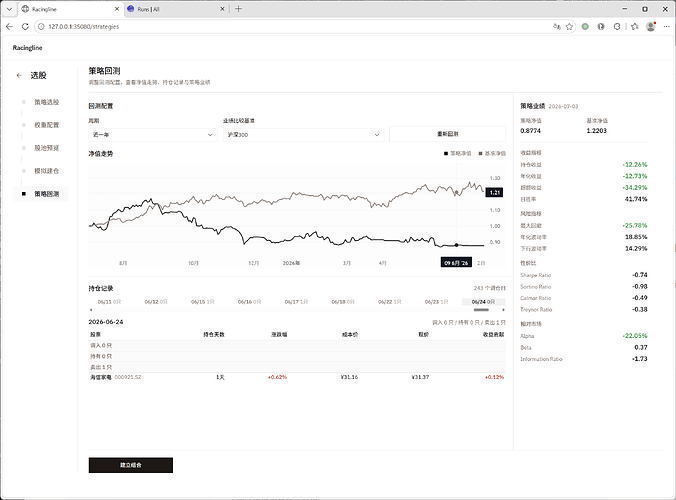
step5. 策略业绩回测。对前面制定的选股规则和调仓规则进行历史行情的业绩验证,清算组合净值并得到评价指标。
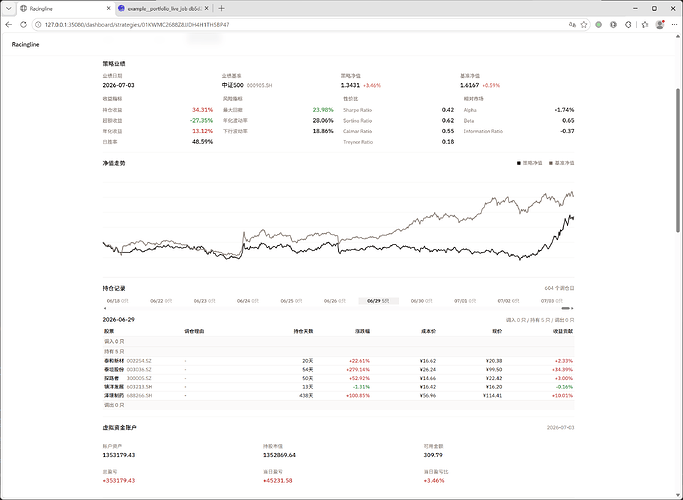
step6. 如果提供给上面的5步得到了理想的历史业绩的组合, 接下来就可以创建这个策略组合进行后续的策略跟踪,看板提供了一些缩略信息, 可以跟踪T日产生的买入信号。而详情页展示模拟建仓后的业绩走势、业绩评价、仓位信息、模拟调仓记录和模拟交割单。
数据资产管理
项目的数据流向:
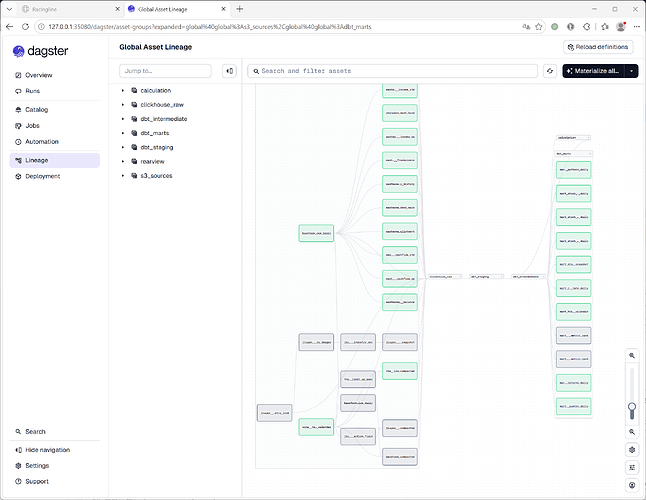
asyncio协程爬虫数据采集数据写入parquet文件后上传到rustfs文件系统。 将rustfs文件系统采用分区替换方案同步到clickhouse数据库的raw层。 经过 dbt 模型转换-> raw源层 → stg层字段清洗 → int 层可复用模型抽象 → mart 层应用数据集市。 由于 clickhouse sql 的表达能力偏向集合处理,在时序处理上有点力不从心,所以增加了一个由 rust 编写的计算引擎驱动的 calc 层,专门针对需要 ema 等滑动平均时序计算的指标做计算能力的补强。 图展示的是基于 Dagster 框架做的数据资产血缘 (数据作业间的依赖关系)。
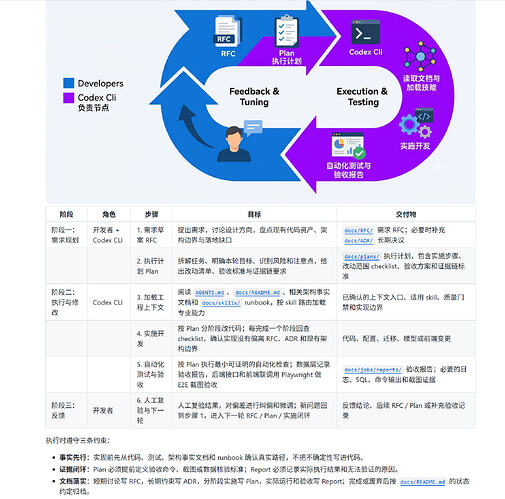
开发过程与 harness-engineering
项目的开发过程仅由 codex + gpt5.5 完成,上述展示的工作台业务仅是工程中工作量较小的一部分,工程的大部分 dirty work 在数据的采集、加工、计算、调度方面。一开始我是只打算做一个数据平台, 后来有强烈的验证欲望想要看我自己针对项目定制的 harness 方案能否驱动更复杂的多 workspace mono-repo, 所以做了这个应用层的尝试。
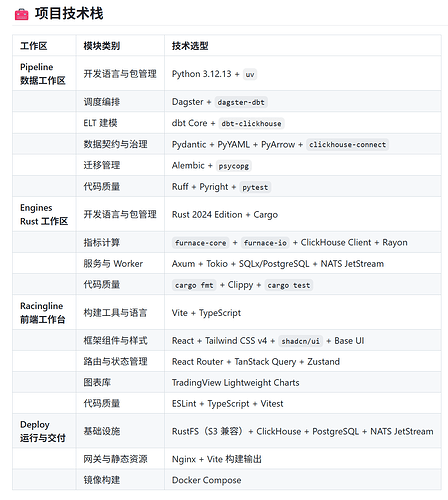
项目根据不同开发语言和领域用途分为三个workspace,所使用的技术如下:
harness是我根据项目特征和 openai 的实施示范为项目定制的,没有采用 superpower 或者其他现成的开源工具集,也没有采用 codex 提供的记忆能力,仅以 AGENTS.md 为文档地图的入口,在项目的 dos 目录下存放这个文档地图的实施事实。 dos 目录基本涵盖了整个项目规划、设计、实施、验收的完整人机交互过程。(理论上只要有足够多的token和同等能力的模型,可以根据 dos 内的信息重建整个代码库?)
其中,项目的执行计划目前有76个 , 也就是执行了至少76次 goal 命令,每次的耗时在45-120分钟之间,取平均估算了一下项目实施工时(不包含我的设计和思考所消耗的时间)大概不到120小,也就是不到10天。
关于工作流
我会先把概要的设计方向跟 codex 进行讨论,记录初步设计的草案,codex 会把草案记录在文档地图的 rfc 目录下 我通过的草案会生成执行计划 plan ,后续会用 goal 命令全权交给 codex 执行。 我负责最终的证据链验收。codex 在执行完成后会在文档地图的 report 目录下给我提供证据链, 例如数据特征报告、后端接口测试调用日志以及前端的浏览器截图画面。 我把开发过程中所有会产生心智负担 的工作都抽象成了skill , 融入了这个执行流程中。 这些 skills 基本都是针对仓库进行定制的,因此维护到仓库内,通过软连接 ln 到 codex 能自动加载披露的 .agents/skills 目录下 。 像数据回填作业补数、数据采集源端API格式测试 还有数据模型字段的维护, 这些都是工作流超大而几乎没有正反馈的 dirty work ,这些就交给定制的 skill 来处理。 而一些工作流 worktree 多分支合并规则、前端debug工具和截图管理、多工作区的版本管理这些辅助性质的工作也适合维护成skill。
关于前端设计
我采用了尽量低饱和度的克制的线条风格来设计 UI,采用符合用户操作直觉的 UX 引导设计, 用户在每个页面的操作成本做到了最大的克制,刻意地分散信息密度,降低整个页面的 AI 味。整体的视觉风格偏寡淡,不抓眼球,比较耐看。 设计过程中我尝试过使用 figma 、 pencil 、super design 等原型图绘制工具来做原型,但是复原过程中总有偏离, 而且这些细节上的纠偏很消耗开发者的精力。
后来我改变了思维, 从设计 → 绘制转变成设计-> 摆放 :
用线框图来表达信息布局。先让codex直接在markdown中通过线框画来用文字的方式画出页面的布局文本的形式可以快速调整,比起原型设计工具的变更成本更低,可以快速制定页面的信息排布和比例。 用真实的工程来做快速原型。接下来创建了一个vite + shadcnui 组件库的简易工程作为快速原型库,让 codex 先 copy 组件库的原型组件封装出业务组件。 摆放代替绘制 。指挥 codex 将业务组件按照第一步设计的线框图布局进行业务组件的摆放。通过上述三步, 可以很巧妙地降低我的精力消耗、让页面减少AI味。
实践中的缺陷
代码品味差,难以阅读。76个goal产生的信息量堆砌在一起容易让人产生抵触情绪。 强依赖 codex + gpt5.5 组合。 在开发过程中我尝试过 opus4.7、4.8 、fable 、 glm5.2、 qwen3.7 和 claude code 的排列组合, 实施效果均不如 codex + gpt5.5 稳定。 其中opus4.7、4.8、 glm5.2、 qwen3.7 觉较为严重, 长程任务中的信息丢失和幻觉非常影响验收效率。 而gpt5.4对项目中的定制skills灵敏度不足, 经常不加载skills就执行任务,导致偏离预期。因此目前这套工程方案还是仅适用于codex + gpt5.5 组合。 过度设计。目前的应用层功能比较简陋,实际上实现这种需求有更轻量的数据支持方案,但过程目标之一所以验证harness方案的落地效果,所以把架构往大了做,造成了一些额外的运维复杂度和硬件成本。 纯手工码了上面的内容,更多的信息可以浏览我的代码仓库,如果有更多功能方面的需求欢迎给我提 pr 或者发起 issue 与我讨论。 如果我的技术分享或者项目对你有用可以给我点个 star 。感谢佬友们的支持。



 lanke 07-04 11:572楼
lanke 07-04 11:572楼