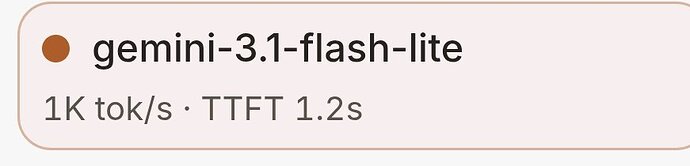
有什么比较便宜的方法能用到 1000token/s 的模型?
Zigzag
2026-07-04 22:39
1
最新回复 (10)
-
 绫娘 07-04 22:461楼
绫娘 07-04 22:461楼 -
 量子Bug 07-04 22:472楼
量子Bug 07-04 22:472楼 -
 Zigzag 楼主 07-04 22:483楼
Zigzag 楼主 07-04 22:483楼 -
Zigzag 楼主 07-04 22:494楼
-
 cocw 07-04 22:495楼
cocw 07-04 22:495楼 -
量子Bug 07-04 22:506楼
-
Zigzag 楼主 07-04 22:517楼
-
 idamie 07-04 22:558楼
idamie 07-04 22:558楼 -
Zigzag 楼主 07-05 13:229楼
-
 神话大萝 07-05 13:2410楼
神话大萝 07-05 13:2410楼

* 帖子来源Linux.do
附近帖子