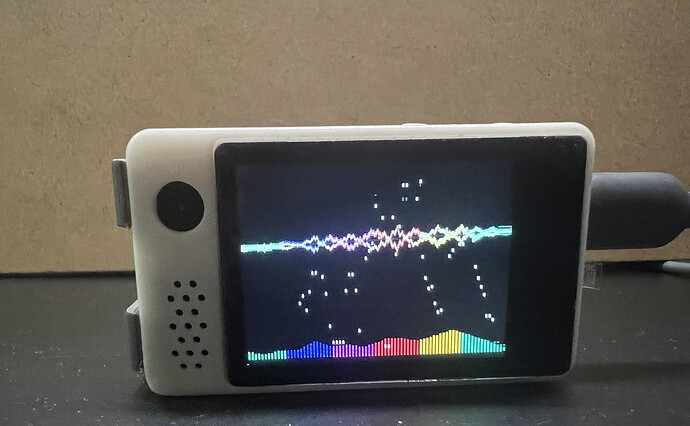
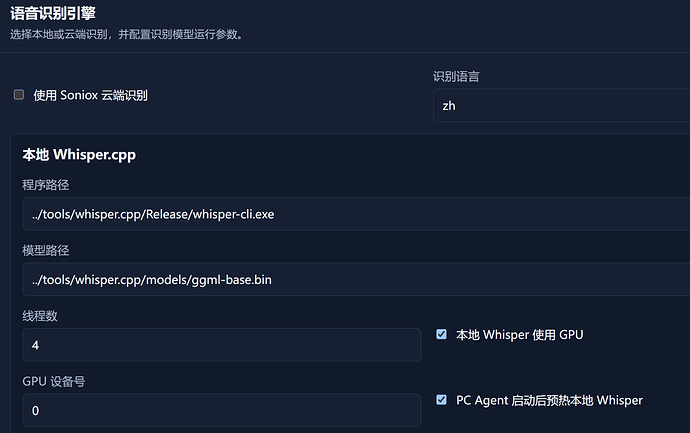
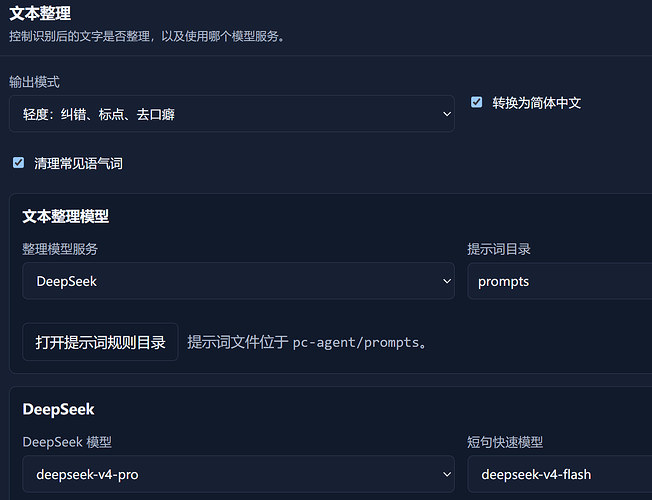
做了一个 ESP32-S3 语音输入小模块:按住说话,松手直接把文字输入到电脑
giter
2026-07-05 14:28
1




最新回复 (9)
-
 Colox 07-05 14:301楼
Colox 07-05 14:301楼 -
 conger 07-05 14:402楼
conger 07-05 14:402楼 -
 xioepp 07-05 14:483楼
xioepp 07-05 14:483楼 -
 server0608 07-05 14:504楼
server0608 07-05 14:504楼 -
 giter 楼主 07-05 14:535楼
giter 楼主 07-05 14:535楼 -
 潇潇 07-05 14:566楼
潇潇 07-05 14:566楼 -
 aureling 07-05 14:597楼
aureling 07-05 14:597楼 -
giter 楼主 07-05 14:598楼
-
giter 楼主 07-05 15:019楼
* 帖子来源Linux.do
附近帖子
- ↑Claude与codex聊天记录互相迁移
- ↑itab也太恶心了,只能说是国内的新建标签页插件都这样……
- ↑gpt 5.6 sol现在可以用吗
- ↑解决了困扰许久的codex降智问题,感谢佬开源,L站大佬太强了!
- ↑【富可敌国】帅API加入L站周末狂欢0.01倍率!
- 📍 做了一个 ESP32-S3 语音输入小模块:按住说话,松手直接把文字输入到电脑
- ↓告别 Terminal!IDEA 也可以爽用 Claude Code 惹
- ↓[富可敌国] 模型优惠最后一天!🔥L 站专属福利继续,注册送额度,充值再送 15%
- ↓你们说的这个灵根果然是好东西啊
- ↓我就想看个电视怎么这么难
- ↓请问一下万能的佬友,我刚刚发的帖子被归到待处理这个类里面去了,我应该找谁帮忙解决一下呀