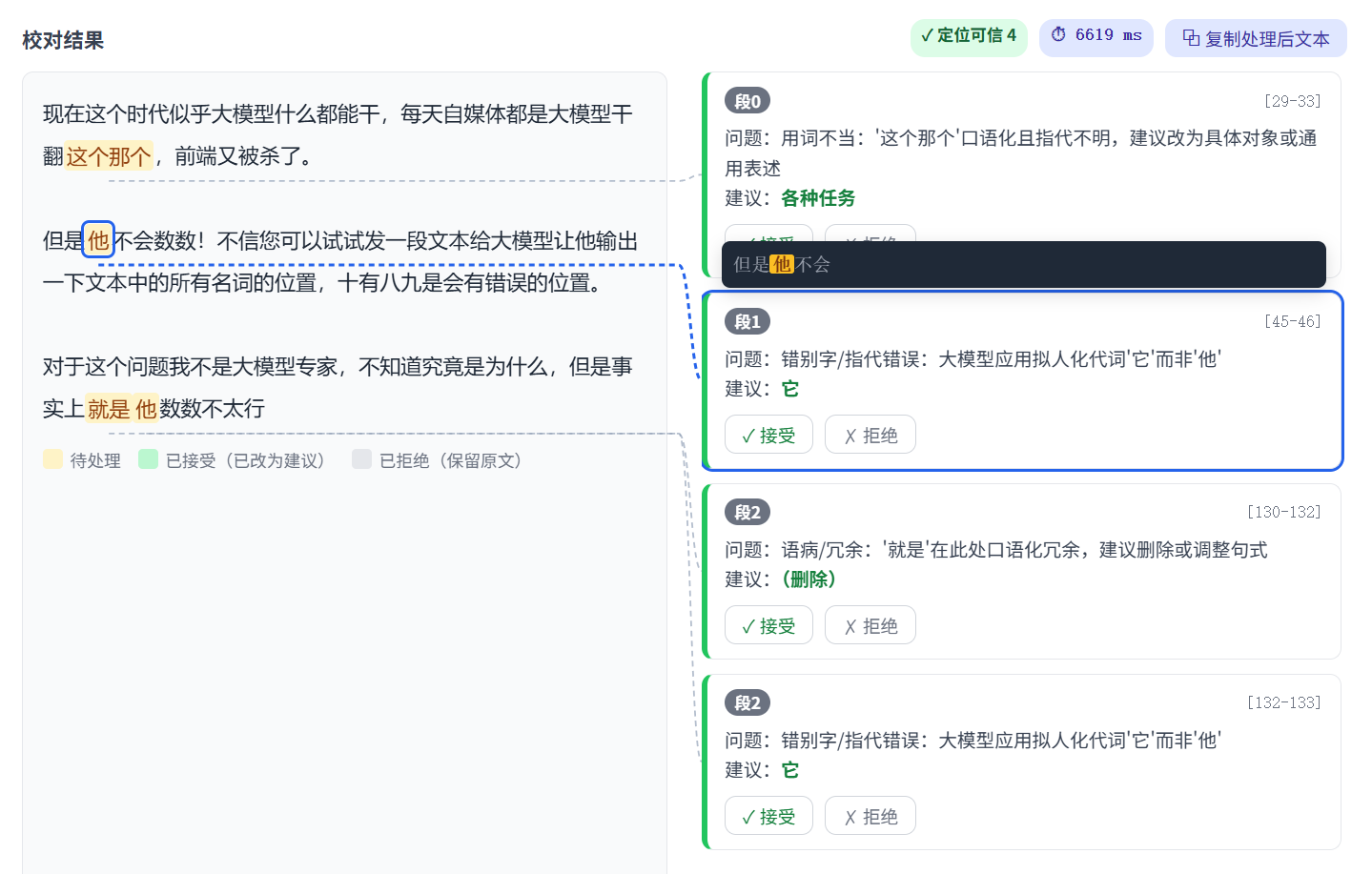
大模型不会数数!违反常识的问题
llej
2026-07-01 10:05
1

最新回复 (21)
-
 pi1ot 07-01 10:101楼
pi1ot 07-01 10:101楼 -
 paopjian 07-01 10:352楼
paopjian 07-01 10:352楼 -
 liulicaixiao 07-01 10:563楼
liulicaixiao 07-01 10:563楼 -
 maplezzz 07-01 10:584楼
maplezzz 07-01 10:584楼 -
 wsseo 07-01 11:055楼
wsseo 07-01 11:055楼 -
 hertzry 07-01 11:396楼
hertzry 07-01 11:396楼 -
 cocogovern 07-01 13:097楼
cocogovern 07-01 13:097楼 -
 jimrok 07-01 13:158楼
jimrok 07-01 13:158楼 -
 xking 07-01 13:529楼
xking 07-01 13:529楼 -
 opengps 07-01 13:5810楼
opengps 07-01 13:5810楼 -
 tanx 07-01 14:1611楼
tanx 07-01 14:1611楼 -
 Rickkkkkkk 07-01 14:1812楼
Rickkkkkkk 07-01 14:1812楼 -
 allanwell 07-01 14:1913楼
allanwell 07-01 14:1913楼 -
 bzj 07-01 15:5714楼
bzj 07-01 15:5714楼 -
bzj 07-01 15:5915楼
-
 tf2 07-01 16:0316楼
tf2 07-01 16:0316楼 -
 mwVYYA6 07-01 16:0517楼
mwVYYA6 07-01 16:0517楼 -
 llej 楼主 07-01 16:5718楼
llej 楼主 07-01 16:5718楼 -
llej 楼主 07-01 16:5919楼
-
llej 楼主 07-01 17:0020楼
-
 darksword21 07-01 17:1321楼
darksword21 07-01 17:1321楼




* 帖子来源V2EX
附近帖子