deepseek降智
猪猪侠
2026-06-30 15:49
1
最新回复 (17)
-
 Bisquiz 06-30 15:501楼
Bisquiz 06-30 15:501楼 -
 瑶瑶发大财 06-30 15:512楼
瑶瑶发大财 06-30 15:512楼 -
 猪猪侠 楼主 06-30 15:553楼
猪猪侠 楼主 06-30 15:553楼 -
 inliver 06-30 15:554楼
inliver 06-30 15:554楼 -
 Martini 06-30 15:585楼
Martini 06-30 15:585楼 -
 风戈 秦 06-30 15:586楼
风戈 秦 06-30 15:586楼 -
猪猪侠 楼主 06-30 15:587楼
-
猪猪侠 楼主 06-30 15:598楼
-
 keeshow 06-30 16:029楼
keeshow 06-30 16:029楼 -
猪猪侠 楼主 06-30 16:0210楼
-
猪猪侠 楼主 06-30 16:0311楼
-
 lingtian 06-30 16:0512楼
lingtian 06-30 16:0512楼 -
猪猪侠 楼主 06-30 16:0813楼
-
 Eeevan 06-30 16:0814楼
Eeevan 06-30 16:0814楼 -
 KenithZ 06-30 16:1315楼
KenithZ 06-30 16:1315楼 -
 Tully 06-30 16:1816楼
Tully 06-30 16:1816楼 -
猪猪侠 楼主 06-30 16:1917楼
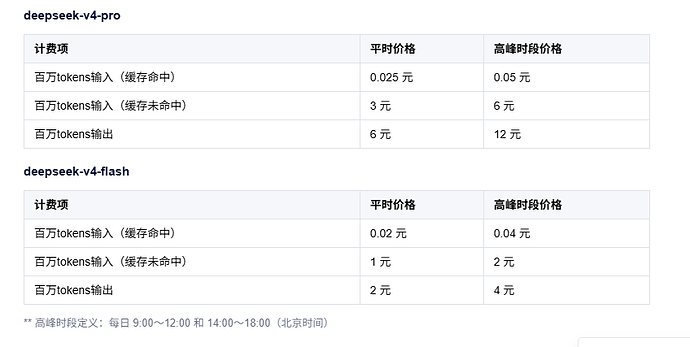
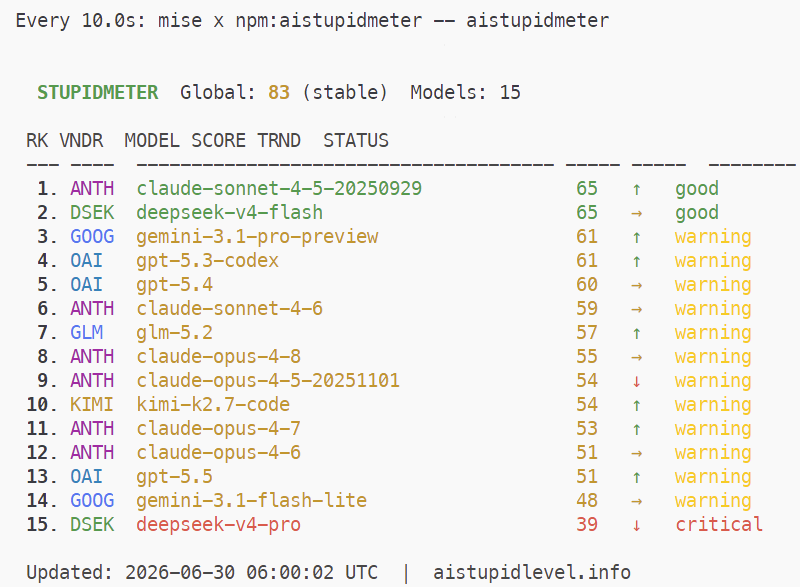
* 帖子来源Linux.do
附近帖子
- ↑佬们 JAVA面试现在还需要会哪些技能呢 帮我补充补充
- ↑京东云薅的GLM在Claude中使用总是罢工是为啥???
- ↑【纯水】还有两个多月姑娘就要出生了,集思广益想个名字吧,我姓张🤣
- ↑开仓济粮,Hlool公益站邀请码
- ↑「Joverna」公益站 grok 模型使用姿势求助
- 📍 deepseek降智
- ↓Macmini m4外接40Gbps硬盘盒,用typec一线连显示器,硬盘盒速度会降为USB 10Gb/s 模式
- ↓实测Visa信用卡秒批秒刷付款 不用等实体卡邮寄
- ↓ccswitch 請求模型不準確 有解決方法嗎
- ↓Grok用来搜什么啊
- ↓【求助/分享】面试阶段汇总 + 德赛西威 offer 选择咨询
飞读
猪猪侠
随机推荐
- anthropic是真的畜官方Claude desktop汉化不了一点
- 美团的大模型LongCat-2.0正式发布了。9.9元 5000万/399元 10亿
- 港美互联走什么线路最好?
- 发现了一个套路,淘宝咸鱼上改大流量套餐,付款了对方说现在不能改了,让我办新的流量卡。。😫
- Safepal 上申请的信用卡被封了, cc 和 codex 都订阅不了👋🏻
- codex cli你们不用吗,为啥都用桌面端
- PayPal 自动付款不走首选卡
- hostdzire 买了三年付的产品 打开管理页面提示 gateway timeout
- 如果现在所有 AI 工具都不能用了,你们会是什么感受?
- 有没有人整理所有屏蔽HK的网站和APP服务