系列前景提要:
我偶然间找着了一个 GitHub 项目,这个 GitHub 项目是针对 Claude Code 泄露的源码进行分析。
之前我看到过很多 Claude Code 源码分析文章,要么太具体深入代码,要么 AI 写的太多导致节奏感不好。
不过这个 repo 给了我很大的灵感和思路,所以我想根据这个 GitHub 写一个完整的系列。
所以我的写作风格会严格把控每一张图,尽我最大的努力做大结构严谨,层次感分明,从架构方面让大家对 Claude Code 有更多的理解。

▲ 图源:Claude Code from Source 首页封面截图
这张封面图充满着反讽意味。
首先左上角的 NO’ REILLY 致敬一个出版社 O’REILLY ,好像在说,没什么是真实的,是一个恶搞。
Alejandro Balderas 本人是 Anthropic 的工程师,在技术社区中,他确实深度参与了 Claude Code的开发工作。但是 Alejandro Balderas 却和 AI 合著了这本书,充满着一语双关的味道。
封面中间一个螃蟹举着一个 .map 封面,意指 Claude Code 泄露 .map 文件这件事情,而且这个 map ,也确实可以认为是一张 .map 的地图。
(纯属我自己胡乱分析的,大家看个乐呵就好)
正文开始
正文开始,大家可以先想一个问题,Claude Code 到底是什么?
传统的 CLI 其本质上就是一个函数,就是一条命令,执行一个操作,获得确定性的输出。
比如 grep ,你执行 grep 的时候不会要同时运行 sed,比如 curl,你也不会下载完东西以后,再根据下载的内容进行补全。
然后 Agentic CLI 出来了。
Agentic CLI 会接受人类自然语言的描述,根据自然语言的提示,来决定使用哪些工具。并且按照具体的情况要求顺序的调用这些工具,获得结果,然后进行循环,直到任务完成或用户停止为止。
于是传统的 CLI 方式大家都不用了,都改为使用 Agentic CLI 了。
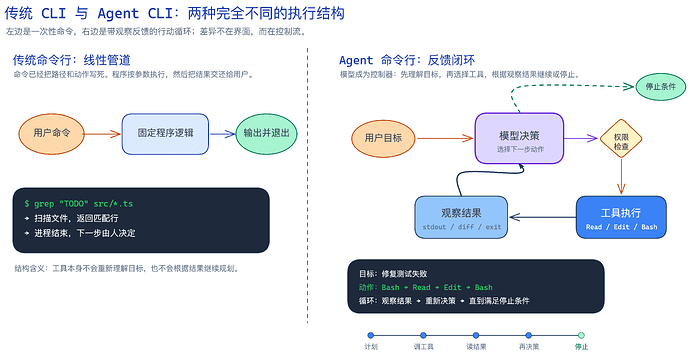
▲ 传统 CLI 是线性管道,Agentic CLI 是围绕模型决策形成的反馈闭环。
由此我们可以给 Agentic CLI 下一个定义:
Agentic CLI 不是一串固定的指令,而是围绕着大语言模型运转的一个循环,模型会在运行时自己生成下一步指令。
Claude Code 是一个 TypeScript 的单体应用,它将终端变成了一个由 Claude 驱动的完整开发环境。Claude Code 就是 Anthropic 对这个想法进行了生产级实现的产品。
这第一节的内容,就是来聊聊抽象出来的 Claude Code 六种心智模型。
六个核心抽象
Claude Code 是建立在六个核心抽象之上的。
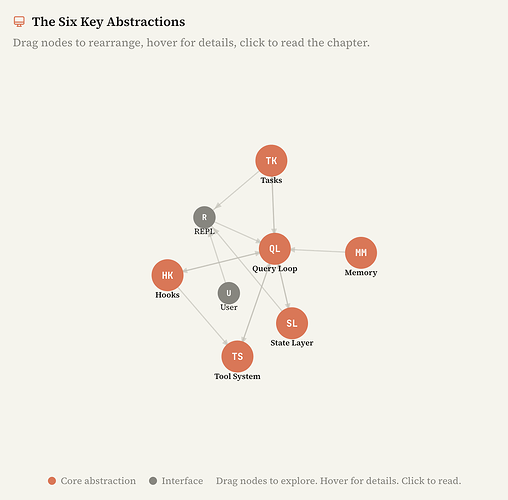
▲ 图源:Claude Code from Source 第一章交互图截图
这六个抽象层面分别是:
Query Loop、Tool System、Tasks、State、Memory、Hooks。
分别对应查询循环、工具系统、任务、状态、记忆和钩子。
而除此之外的比如几百个工具函数、终端渲染器、Vim 模拟器、成本追踪器这些,它们的本质上都是在服务这六个抽象。
下面我分别来跟大家解释一下。
Query Loop:整个系统的核心
第一个抽象是 Query Loop。Query Loop 位于 query.ts,大概 1700 行代码。这是一个异步生成器,是整个系统的核心。
所以,Claude Code 的核心,就是一轮一轮地跑:
调用模型 → 接收流式响应 → 收集工具调用 → 执行工具 → 把工具结果追加回上下文 → 然后继续下一轮。
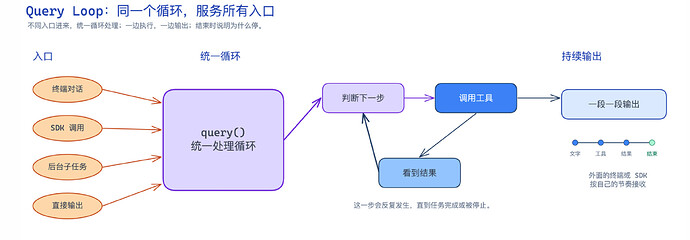
▲ Query Loop 是 Claude Code 的统一处理循环:不同入口汇入同一个 query(),它一边执行任务,一边把结果持续输出给外部。
这里需要注意一点的是:Query Loop 不只是 REPL 的内部实现。
REPL 是什么?REPL 是 Read-Eval-Print Loop 的缩写。中文可以理解成:读取、执行、输出、循环。它是一种交互式的命令环境。
普通的 REPL 、SDK 调用、sub-agent 、无头模式 --print 这些,其实都在使用 Query Loop 这种方式。
不过 Claude Code 没有给这些入口各写一套 Agent 逻辑,而是把它们最后都汇入同一个 query() 循环,然后用 for await 方法,一段一段地消费大模型通过工具调用输出的事件。
如果用伪代码,大概是这样的:
for await (const event of query(input)) {
render(event)
}
如果用生活中的例子来解释:大概是快递分拣包裹中,有一个集装箱,机械臂可以一轮一轮实时把包裹进行分拣,分拣完成后再装箱,最后进行运输。
Agent 在调用 query 方法对用户的输入进行处理,处理完成后会产生原始的 event 事件,这些 event 事件是大模型产生的原始事件,这些事件无法直接返回给用户,需要 Agent 对其进行一层渲染、包装一层 Message 事件后,再返回给用户。
我用 claude -p 实际跑了一下,来看看具体的 Message 事件长啥样,这样会帮助你更好理解(数据已脱敏)
{"type":"system","subtype":"init","cwd":"<redacted>","session_id":"<redacted>","tools":["Read","Edit","Bash","..."],"model":"<model>"}
{"type":"system","subtype":"status","status":"requesting"}
{"type":"stream_event","event":{"type":"message_start"}}
{"type":"stream_event","event":{"type":"content_block_delta","delta":{"type":"text_delta","text":"你好!"}}}
{"type":"assistant","message":{"role":"assistant","content":[{"type":"text","text":"你好!"}]}}
{"type":"stream_event","event":{"type":"message_delta","delta":{"stop_reason":"end_turn"}}}
{"type":"result","subtype":"success","result":"你好!","stop_reason":"end_turn"}
开头的 system/init 表示 Claude Code 开始初始化会话;
system/status requesting 表示 Claude Code 开始请求模型;
stream_event/message_start 表示模型开始返回流式响应;
stream_event/content_block_delta 表示模型在持续输出;
assistant 是 SDK 整理出来的 assistant Message ;
stream_event/message_delta 是消息级别的更新;
最后的 result/success 表示整个 query() 执行完成。
整个循环是一个 async generator,也就是异步生成的。
啥意思呢?
简单来说,它不是一次性跑完再返回结果,而是一边运行,一边不断产出新的 event 事件。
(这些事件可以是模型输出的一段文本,可以是一次工具调用,可以是工具执行结果,也可以是最后的停止事件。)
这种设计会存在几类好处:
第一,输出节奏可控。
Agent 执行时会不断产生东西:模型的文本、工具的调用、工具执行的结果、状态的变化。如果用普通事件回调,循环里面会不管循环外面处理得快不快,一直会产生新的 event 事件。
如果用户终端处理不过来,很可能会导致消息积压。
第二,用户需要中断时,能够及时响应。
如果用户按了 Ctrl+C,或者外部调用方取消了请求。
因为这时候模型调用可能还没结束,工具可能还在跑,子任务也可能还在继续执行。
这时是一堆 callback 到处飞的话,很容易出现一个问题:表面上停了,实际上后台还在继续执行。
最后到底是用户取消、工具调用失败,还是系统异常,就说不清楚了。
async generator 的好处是,它有一个明确的停止信号可以做判断。
用户希望取消执行,Agent 就可以沿着这条执行链路进行收尾:停止继续产出事件,通知正在运行的任务中断,并把最后的停止原因标记为用户取消。
第三,也是最重要的,它会说清楚停止的原因是什么。
任务停止后,在最后输出的 result Message 里会带着 stop_reason。
它可以直接根据这个结果决定下一步怎么处理。
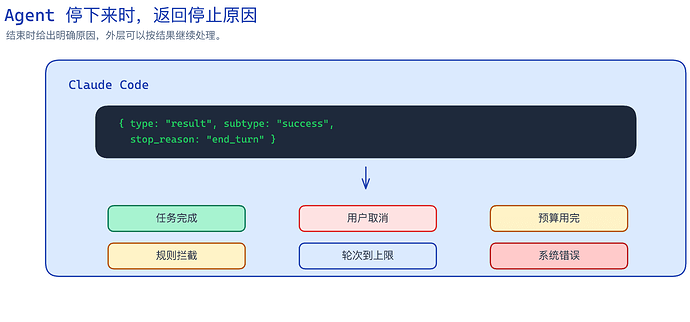
▲ Claude Code 停止原因
它能够清晰的表明到底因为啥而停止,而不是告诉用户,任务停了。
2. Tool System:工具系统
第二个抽象是工具系统,源码在Tool.ts, tools.ts, services/tools/ 中。
工具就是 Agent 在电脑世界里到底能干哪些活。
比如我们日常使用的读文件、跑 shell、编辑代码、搜索网页,都是在调用工具。
这句话虽然看起来很简单,这其实里面是一套完整的工具系统,复杂度很高。
Claude Code 中的每个工具都实现了丰富的接口,这些接口都涵盖了身份、模式、执行、权限和渲染等方面。
这里需要先给各位小伙伴介绍两个概念:一个是工具执行器,一个是流式调度器。
工具执行器比较好理解,它就是负责执行工具。比如 Read、Write、Bash、Grep 等。
但工具执行器会在执行的时候,将工具调用分为串行执行和并发执行。
比如读文件通常可以并行执行,但写文件、跑会修改状态的命令,就不能随意并行执行。
而流式调度器 更像工具执行器里面的一种优化机制,或者一种执行策略。
它关心的是:能不能在模型还没完整输出完之前,就提前启动某些工具?
比如模型刚刚输出一个 Read 调用,如果 Read 是并发安全的,流式调度器就可以马上启动它,Agent 就可以先去读文件。
此时模型还在继续执行,但读文件已经结束了。
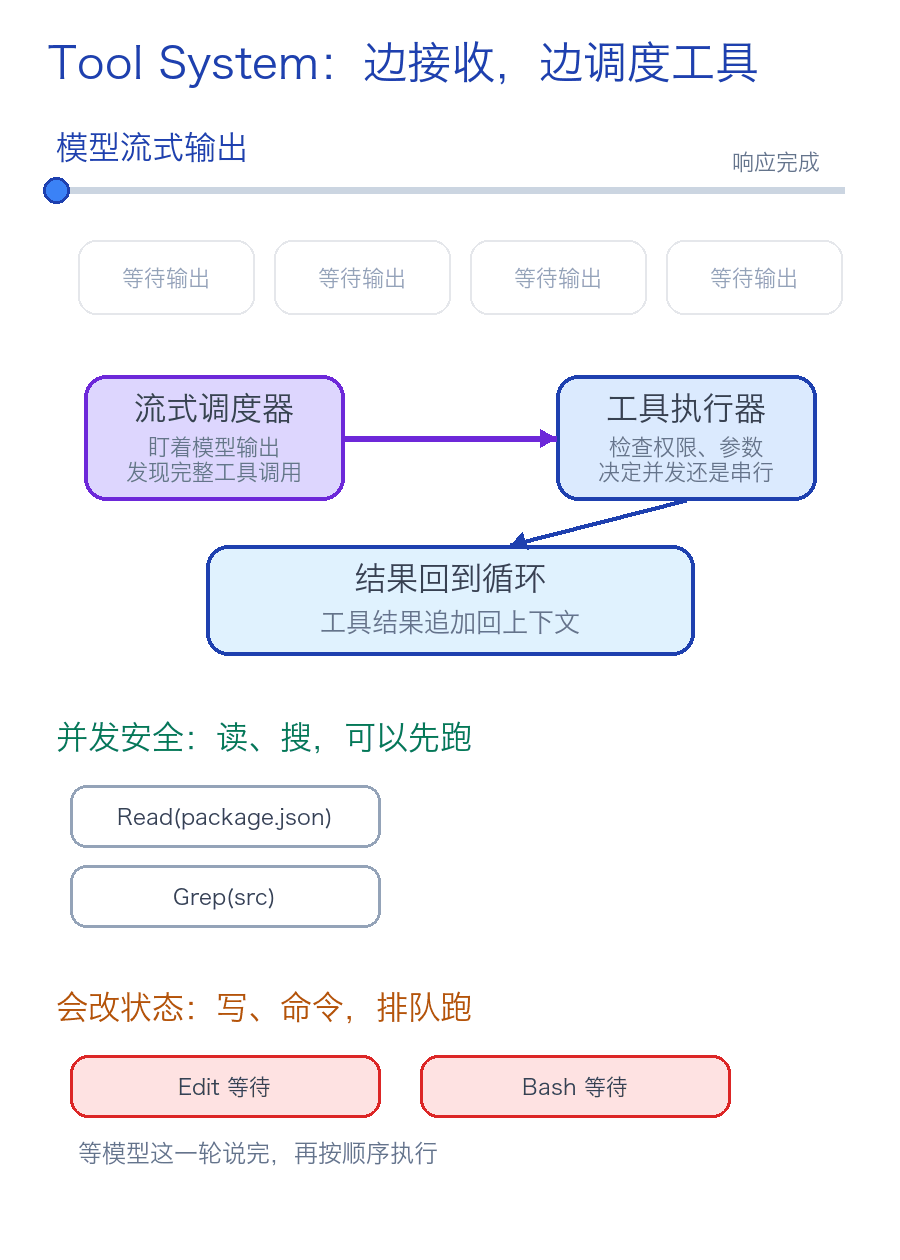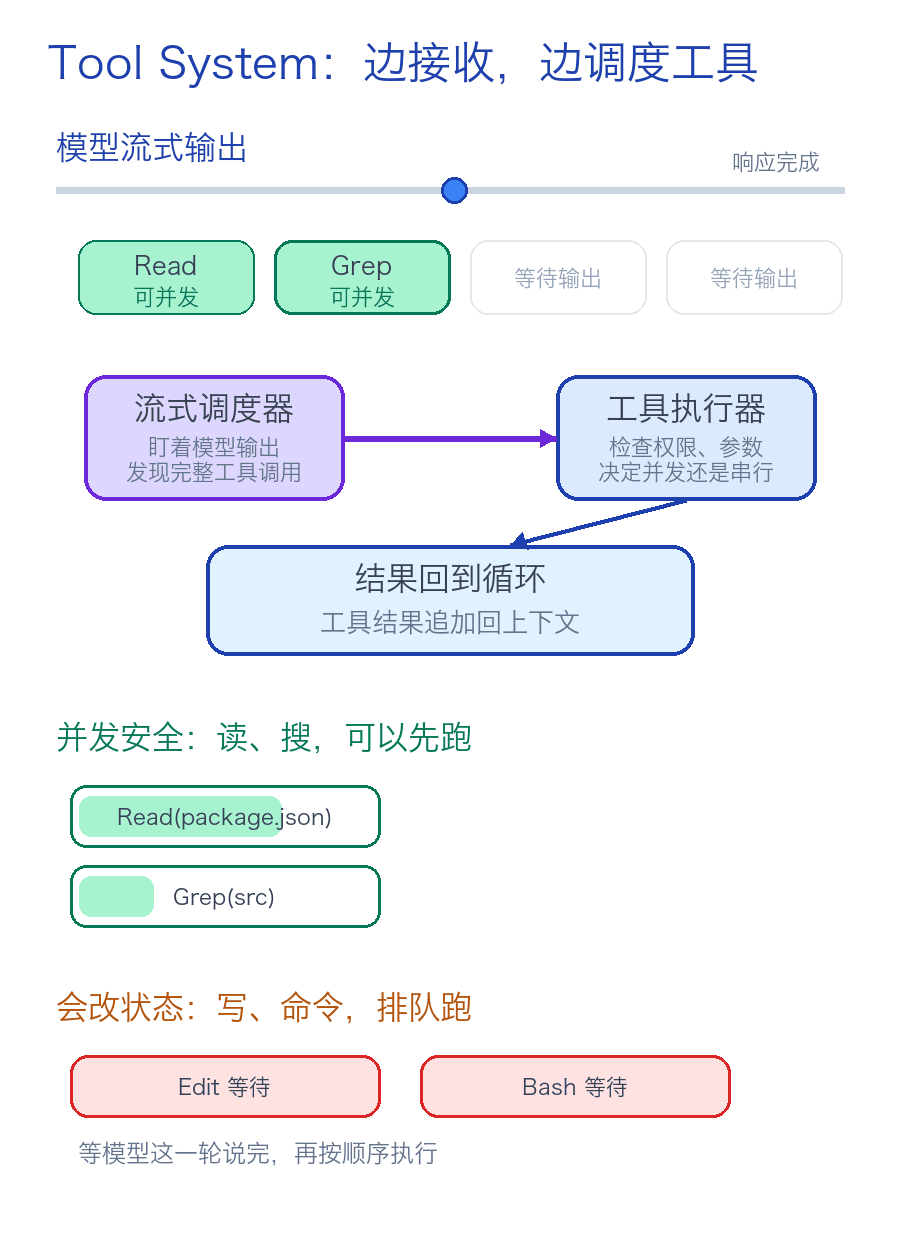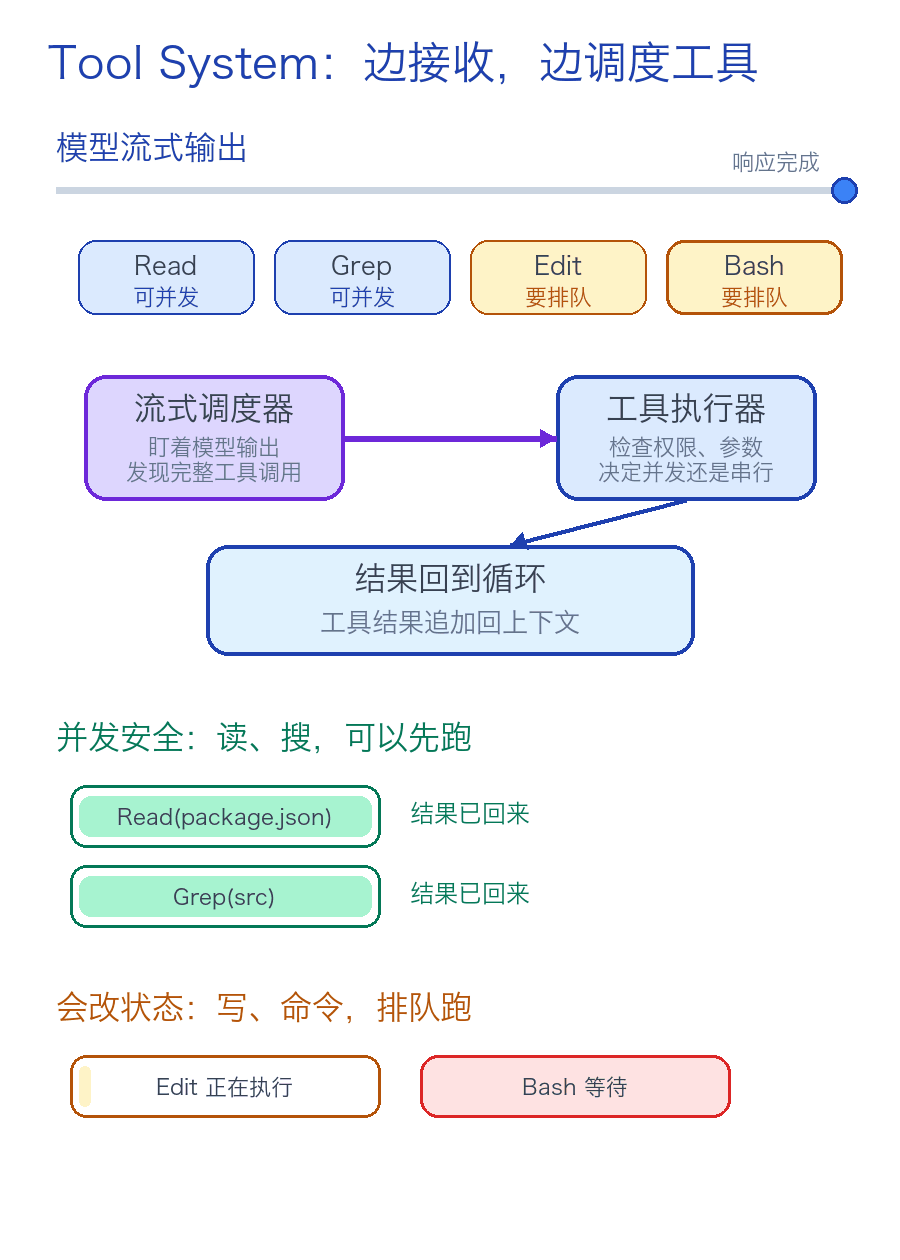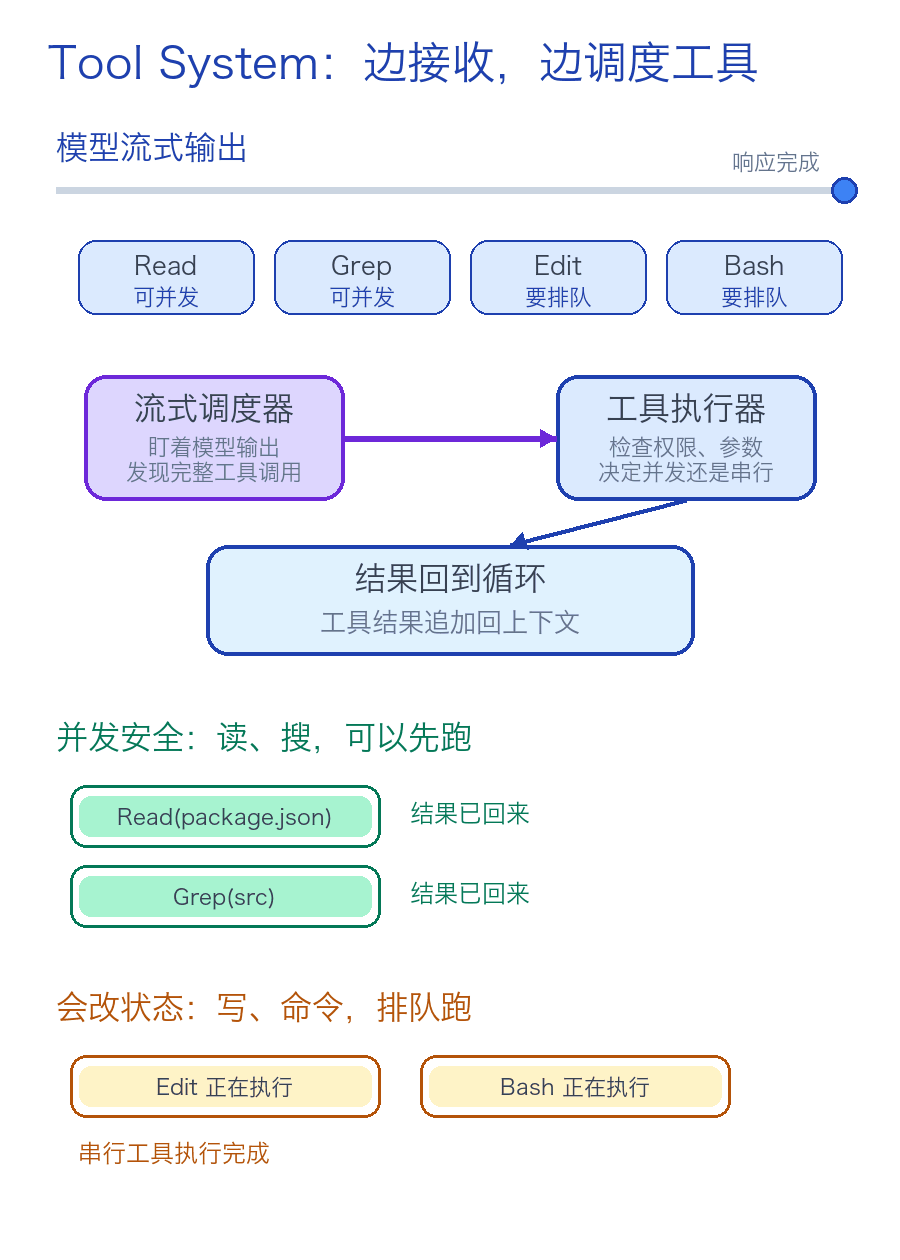
▲ 工具系统可以边接收模型输出,边判断哪些工具可以直接使用。
Claude Code 把工具执行和模型流式输出揉在了一起。
3. Tasks:后台任务和 sub-agent
第三个抽象是 Tasks。源码在 Task.ts, tasks/ 文件中。
Task 主要是后台的执行单元,它用来承载 sub-agent 。
每个 sub-agent 都有一个状态机:包含下面这几种状态 。
pending -> running -> completed | failed | killed
也就是等待、运行、完成、失败、被杀掉。
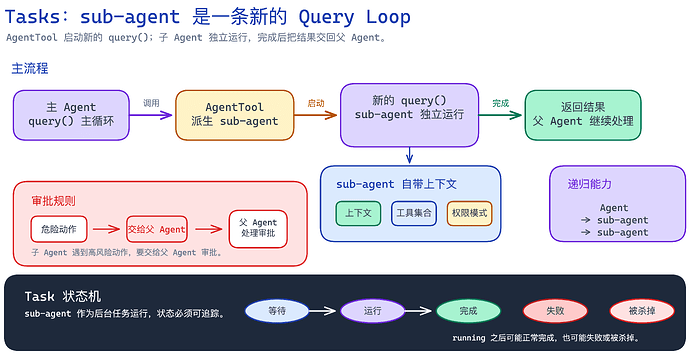
▲ sub-agent 是由 AgentTool 启动的一条新 Query Loop。它有自己的消息历史、工具集合和权限模式。
重点在于 AgentTool。
当 Claude Code fork 出来一个 sub-agent 的时候,fork 出 sub-agent 的被称为父 Agent,sub-agent 和父 Agent 走的是同一套 query loop ,只不过 sub-agent 是调用 Query 方法来启动的新的 query loop 。
这个新的 query loop 有自己的上下文、自己的工具集合、自己的权限模式,所以它也是一个小的 Agent。
这种 fork 的方式就给 Claude Code 带来了递归能力:
一个 Agent 可以代理给另一个 Agent,另一个 Agent 还可以继续向下进行代理。
但这里也存在一定的危险性,因为一旦 sub-agent 能自己做决定、自己跑命令、自己改文件,系统就有可能失控。
所以后面权限系统里有一个很重要的 bubble 模式,这个后面会讲到。
意思是:sub-agent 遇到危险动作,不能自己批准,需要进行上报,让父 Agent 或用户来决定。
这是多 Agent 系统里很重要的红线。
4. State:两层状态
第四个抽象是状态。
Claude Code 有两层状态。
第一层是一个可变单例 STATE状态
它保存的是会话级基础状态,比如当前工作目录、模型配置、成本追踪、session ID,一共大概 80 个字段。
会话级大家理解是什么意思吧。当你在 Claude Code 每开一个窗口,其实都是 session 级。
session 会记录下面这些状态(一部分):
当前在哪个目录运行
现在用哪个模型
这次会话的 session id 是什么
已经花了多少钱
已经用了多少 token
当前权限模式是什么
当 Claude Code 启动时,会把这些信息放进 STATE:
STATE.cwd = 当前工作目录
STATE.sessionId = 本次会话 ID
STATE.model = 当前模型
STATE.permissionMode = 当前权限模式
后面如果要改,就直接改这个对象本身就可以。
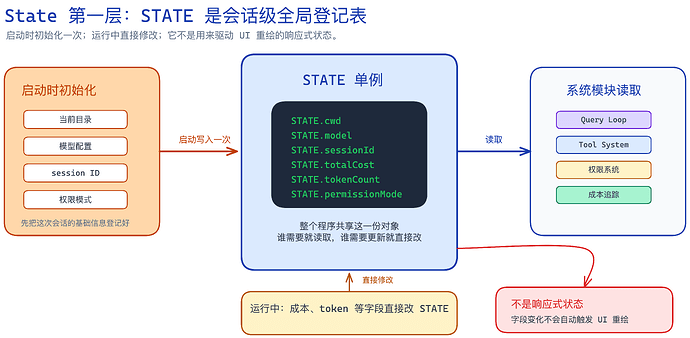
▲ 第一层 STATE 更像一张会话级运行登记表:启动时初始化,运行中直接修改,系统模块按需读取。
第二层是 UI 的界面状态,里面会有这些设定。
新的消息来了
输入模式变了
正在等待用户批准工具调用
进度条更新了
模型正在输出
这些状态改变之后,UI 就要跟着改。
React 这门语言里面,有一个叫做 Zustand 的东西,这是一个 React 的状态管理机制,这个机制来驱动着这些界面状态的改变。
伪代码如下
const useStore = create((set, get) => ({
messages: [],
inputMode: "normal",
addMessage: (msg) =>
set((state) => ({
messages: [...state.messages, msg],
})),
setInputMode: (mode) =>
set({ inputMode: mode }),
}))
很简单,就一个 get、 set 方法,通过简单的 set/get 更新和读取,UI 可以监听这些变化。
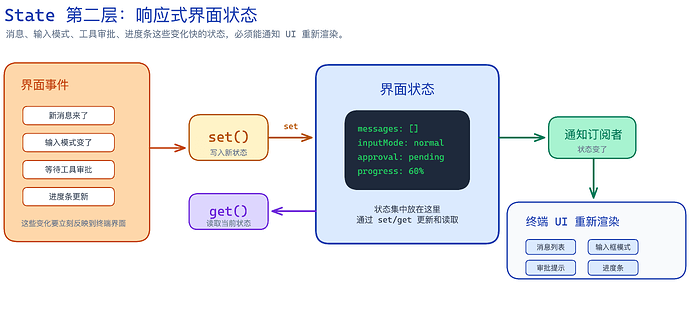
▲ 通过 set() 写入,通过 get() 读取,状态变化后通知 UI 重新渲染。
界面状态这里是用了**响应式(reactive)**的设计,原因也比较简单,因为 UI 状态的改变是实时的。
但不是所有状态都应该 reactive。
像是上面的 State 状态的改变,就不是响应式;而 UI 状态这种需要实时改变的,就需要响应式设计。
5. Memory:跨会话的上下文
第五个抽象是 Memory,在 memdir/ 路径下。
memory 就是 Agent 在 session 间的持久上下文。
原文说 Claude Code 的记忆有三层,Claude 官方也说了是有三层。
但我认为应该是有四层,最后一层其实算团队级。
- 用户级:
~/.claude/CLAUDE.md,对于 Claude 全局生效。
- 项目级:仓库里的
CLAUDE.md,对于项目全局生效。
- 目录/模块级:业务模块路径中的
CLAUDE.md,对于模块全局生效(官方把这一层归到了项目集里面)
- 团队级:通过软连接实现,普通开发者一般不会直接维护。
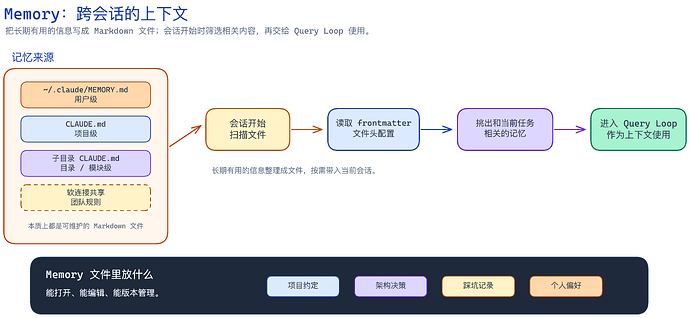
▲ Memory 把长期有用的信息写成 Markdown 文件,会话开始时筛选相关内容,再交给 Query Loop 使用。
每次会话开始时,系统会扫描这些 memory 文件,解析 frontmatter,再让 LLM 判断哪些记忆和当前对话相关,再进入 Query Loop 循环中。
项目约定、架构决策、调试历史、个人偏好这些,都适合沉淀成为 Memory,并且 md 格式是一份能打开、能编辑、方便版本管理的文件。
我现在有一种想法,或许 Agent 记忆最好的形态就是可维护的 Memory.md 。
6. Hooks:生命周期拦截器
第六个抽象是 Hooks,在 hooks/, utils/hooks/ 路径下。
Hooks 是用户自定义的 Claude Code 全生命周期的拦截器。
原文说,Claude Code 的 hooks 会在 4 类执行类型、27 个不同事件上触发。
这 4 类包括 shell 命令、一次性 LLM prompt、多轮 Agent 对话、HTTP webhook。
如果你熟悉 Java Spring 框架的话,这个 Hooks ,就很像 Spring 中 AOP 的设计理念。
但是还不完全一样,Spring AOP 拦的是 Java 方法调用,而 Claude Code Hooks 拦的是 Claude Code 预定义的生命周期事件,比如工具调用前后、prompt 提交、会话结束等。
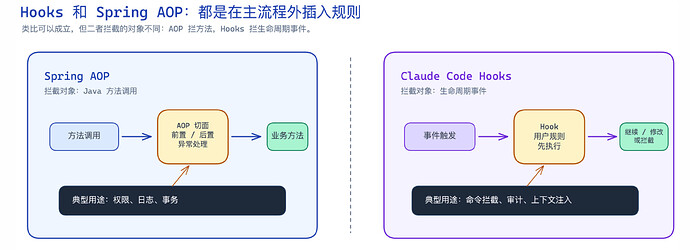
▲ Hooks 和 Spring AOP 异同情况。
Hooks 可以做很多事:阻止工具执行,修改输入,注入额外上下文,甚至直接阻塞整个 query loop。
更有意思的是,权限系统本身也部分通过 hooks 实现。
比如 PreToolUse hook 可以在交互式权限提示出现之前,就拒绝某个工具的调用。
一次 Claude Code 的完整请求
下面是一次 Claude Code 的完整请求,从用户发送消息请求开始。
用户输入:“给登录函数加错误处理”,然后按下回车。
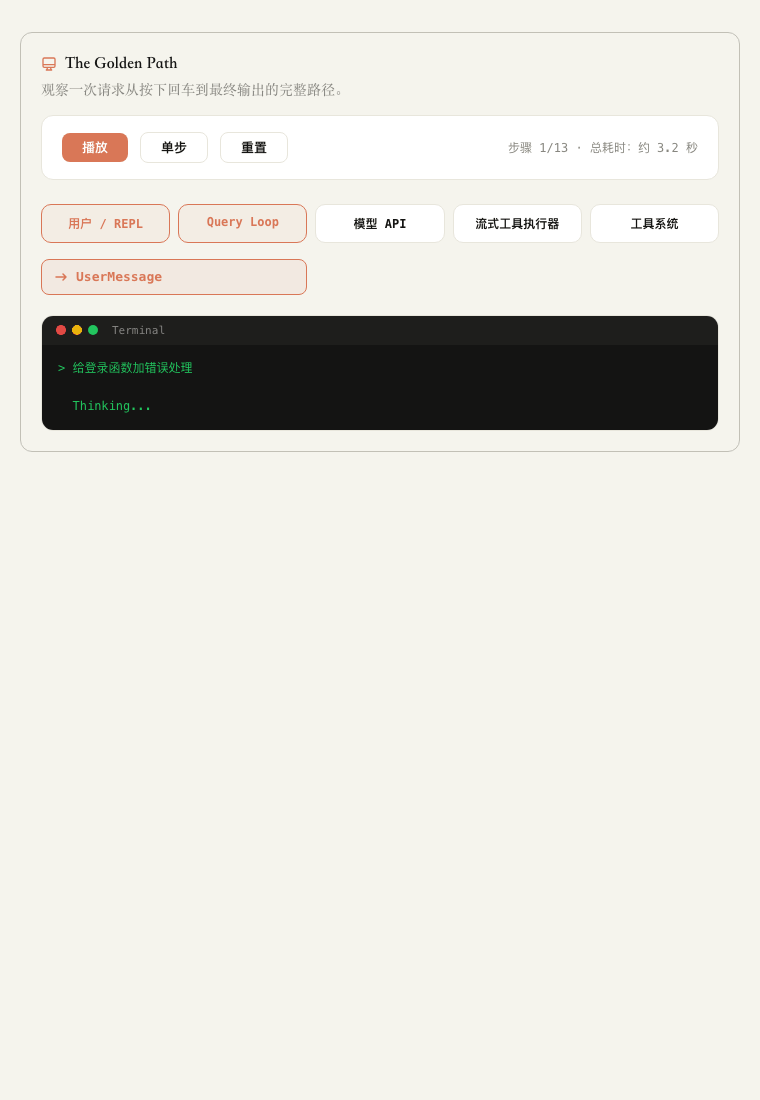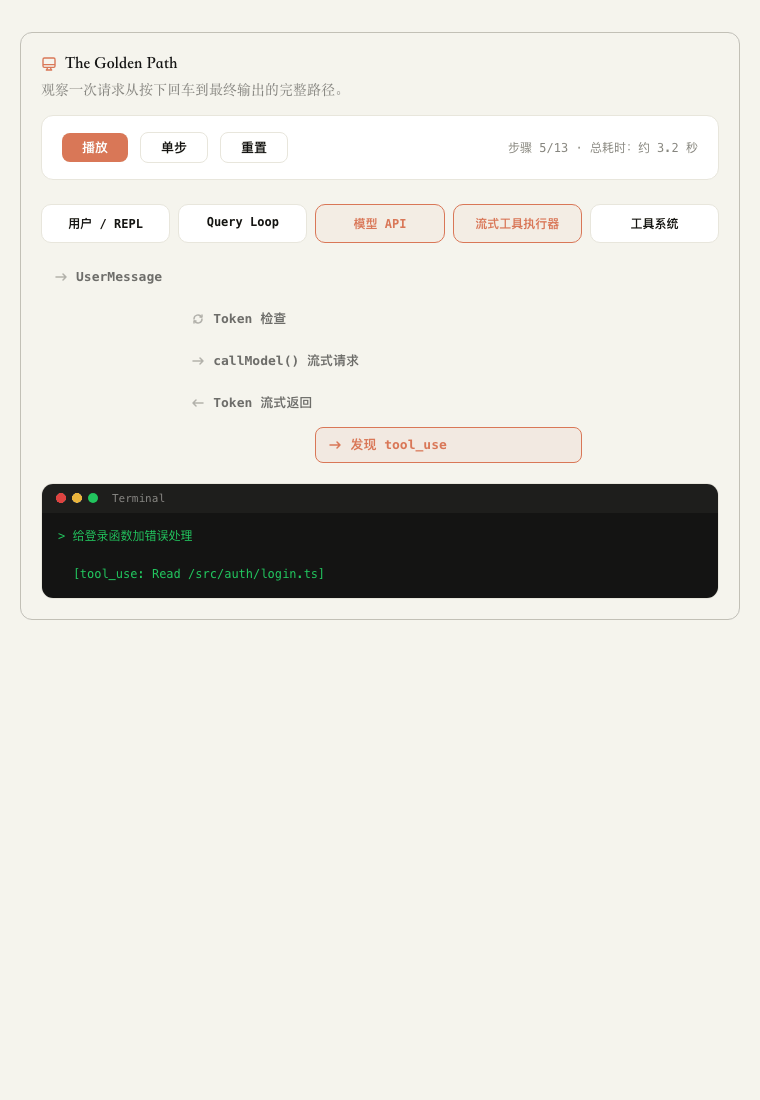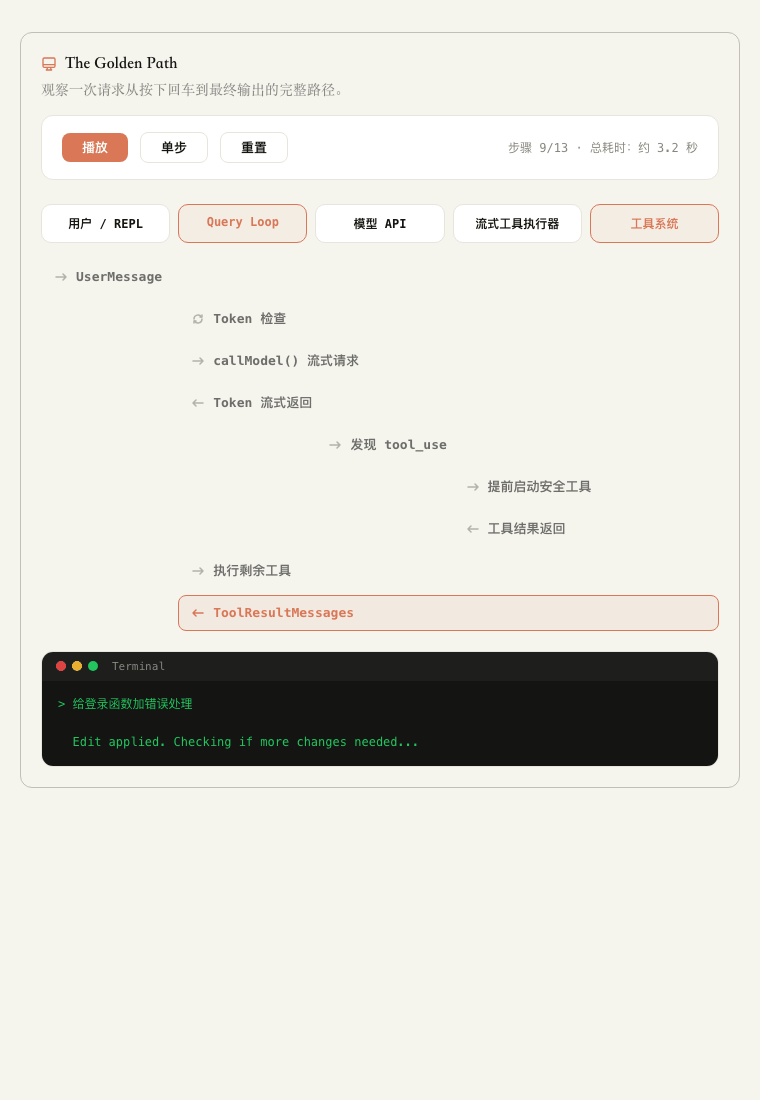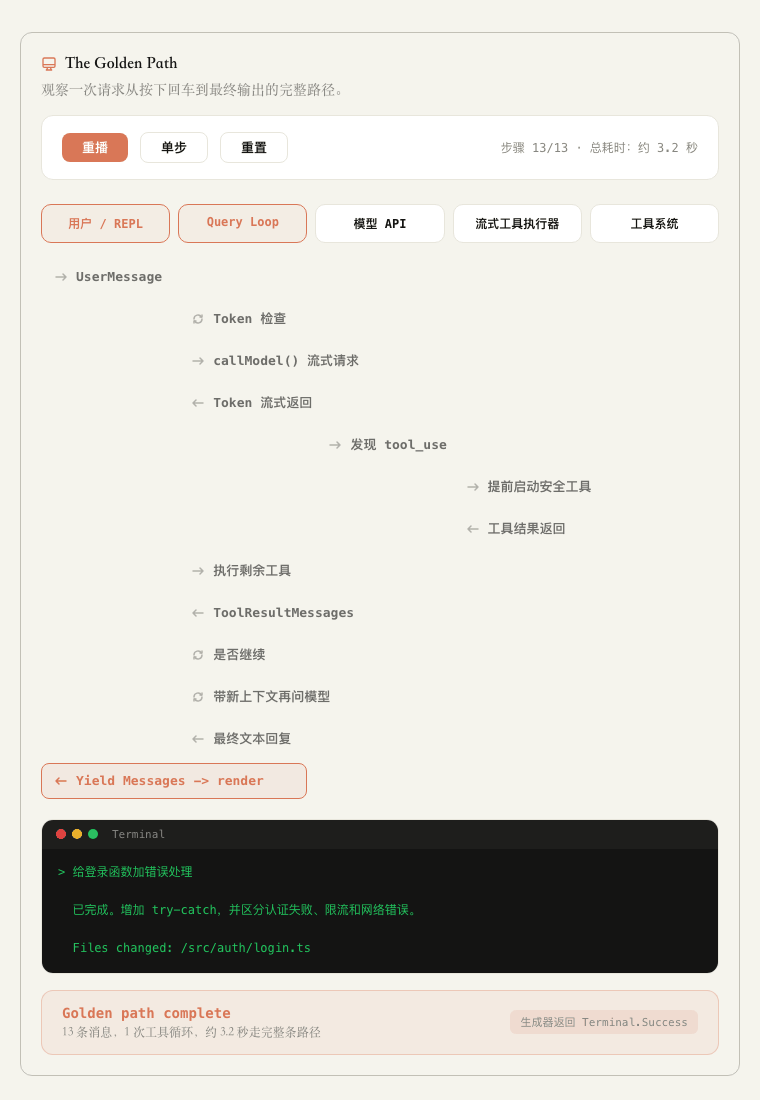
▲ Golden Path 动态演示:一次请求从 REPL 进入 Query Loop,经过模型流式响应、工具执行,再回到终端输出。
完整的静态效果如下。
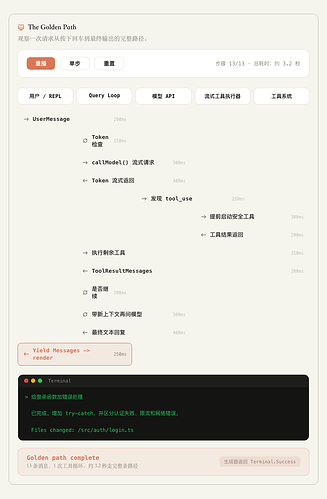
▲ Golden Path 静态完整路径,方便对照
这条路径大概是这样:
用户在 Claude Code 终端输入任务。
REPL 把消息交给 Query Loop。
Query Loop 会调用模型 API。
模型流式返回内容和工具调用。
如果模型要读文件、改文件、跑命令,就交给流式调度器。
工具系统再执行具体的动作。
工具执行的结果会沉淀成为 session 上下文。
Query Loop 带着新上下文再次调用模型。
直到模型不再请求工具,或者外部条件让它停下。
整个执行过程中有三点需要注意。
第一,query loop 是 generator,不是 callback chain。callback chain 也是回调链,一个函数里面有无数个回调函数。
callback chain 的伪代码如下:
runAgent(input, {
onText(text) {},
onToolCall(tool) {},
onToolResult(result) {},
onDone(reason) {},
onError(error) {},
})
callback chain 最大的弊端,是最外层的 runAgent 方法,没有里面回调函数的执行权。
啥意思呢,就是说里面的函数如何执行,外层的 runAgent 无法控制,他只起到被通知执行完成的作用。
而 query loop 不一样,他是用 for await 从里面拉消息的。
for await (const msg of query(input)) {
render(msg)
}
外面每次循环取一条消息,当外面处理完这一条消息后,才继续处理下一条。
callback chain 是“里面主动推”。
generator 是“外面主动拉”。
也就是说 callback chain 和 generator 最大的区别是控制权的归属。
在 query loop 结构中,这意味着终端 UI 的消费速度会影响生成速度。
这块设计它有点像 TCP 滑动窗口背后的思想:接收方处理不过来,发送方就不能无限制发送请求。
第二,Claude Code 不一定等模型整句话说完,才开始执行工具。
一般的做法是这样的:
模型完整输出一段回复,Agent 看完回复,发现里面有工具调用,然后开始执行工具,工具执行完成后,再把结果交回模型。
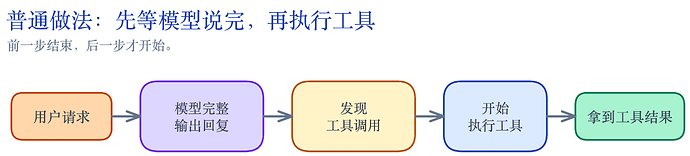
▲ 普通串行方式:模型先完整输出,系统再发现工具调用,然后才开始执行工具。
Claude Code 不是这样做的,Claude Code 有个 StreamingToolExecutor ,它不会傻等模型整段回复结束后再调用相应的工具。
只要它看到一个工具是并发安全的,就可以先执行,比如 Read 和 Grep 。
当模型还在继续生成的时候,文件可能已经读完了。原文把这叫 speculative execution,择机执行。
不过,这种方式也有代价,代价是有可能会重跑,白白消耗 token 。
因为如果后面模型输出改变了前面的结果,那么前面的结果可能要丢掉,虽然这种情况出现的次数比较少,但也不能忽视。
这是 Claude Code 在用可能浪费的算力,来换取整体延迟性的降低。
第三,整个循环是可重入的。
当模型在调用工具后,执行结果会被添加到当前窗口的上下文中,然后循环依据上下文的消息,调用工具继续执行,结果再写回上下文中。比如下面这个例子
用户提问
-> 模型判断:我要读文件
-> 工具读文件
-> 读到的内容放回上下文
-> 模型再看这些内容
-> 模型判断:我要改文件
-> 工具改文件
-> 修改结果再放回上下文
-> 模型再看结果
-> 模型判断:可以结束
-> 最终回复用户
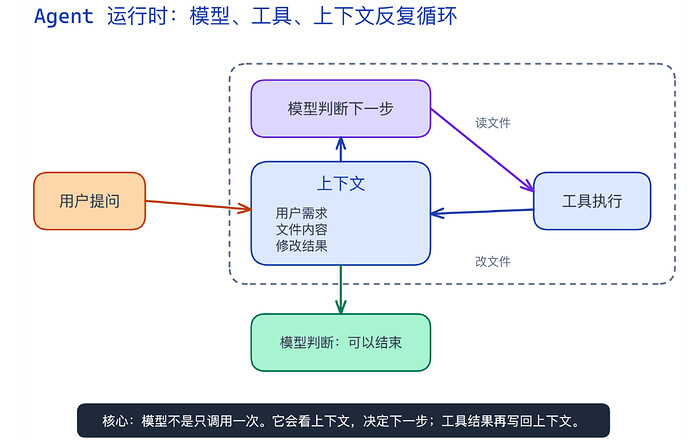
▲ Agent 运行时循环:模型看上下文决定下一步,工具结果再写回上下文。
权限系统
Claude Code 能在你机器上执行任何 shell 命令。
它能改文件,能开子进程,能发网络请求,能改 git 历史。
所以如果没有权限系统对 Agent 进行控制,这就是灾难。
我经常看到非常多的国内小伙伴直接 Bypass permissions 开着跑,而美其名曰你都用上 AI 了,还能怕它搞出事儿来么。
但据我所知,国外很多开发者是不会轻易开这个权限的,我看过 OpenAI 发布会上的开发者用的也只是 acceptEdits。
Claude Code 总共有七种权限模式,从最放开到最保守大概是这样:
(需要注意的是,这是源码层面的权限模式,而不是你在 Claude Code 中可以切换的模式)
模式 |
含义 |
|---|
bypassPermissions |
全部放行,不做检查,主要是内部或测试用 |
dontAsk |
都允许,但仍然会记录日志。 |
auto |
用一个轻量 LLM 分类器判断该 allow 还是 deny |
acceptEdits |
文件编辑自动批准,其他操作仍问 |
default |
标准交互模式,每个关键动作让用户确认 |
plan |
只读模式,所有写操作都禁止 |
bubble |
sub-agent 不自己决定,把权限上抛给父级 |
当工具调用需要权限时,其解决过程遵循严格的流程:

▲ Claude Code 权限解析动态演示:Hook、工具自检、权限模式会依次参与决策。
bypass/dontAsk/acceptEdits/plan 这四个策略是写死的静态策略。default 是人来做每个确认。bubble 是每次都往上抛,由父 Agent 做决定。
这块需要说一下的权限模式是 auto。
auto 模式在判断前都会额外调用一次轻量 LLM,让这个 LLM 来判断是否符合用户原始意图。
所以 auto 本质上是在全手动确认和权限完全放开之间,加了一层自动审批。
如果用户让它改 bug ,读文件、跑测试、改相关文件可能合理。
但如果它突然要删目录了、改 SSH 配置了,就应该停下来等用户确认。
sub-agent 默认走 bubble 模式也很关键。
bubble 就是冒泡,想象一下水里的气泡是否会浮到水面上,bubble 模式是一样的,而水面就是父 Agent。
因为 sub-agent 不能自己批准自己的危险动作。它要向上层 Agent 汇报,上层 Agent 根据自身的权限判断是否向用户申请。
多 Provider 架构
Claude Code 是一种 multi-provider,也就是多 Provider 的架构。
Claude Code 可以通过四种不同基础设施路径访问 Claude。
直接 API、AWS Bedrock、Google Vertex AI、Foundry。
但这些差异对系统其他部分是透明的,系统的其他部分不会知道,也不关心多 Provider 。
▲ 多 Provider 的架构模式
Anthropic SDK 给不同云厂商都做了适配 wrapper,这些 wrapper 对外暴露同一套接口。
getAnthropicClient() 是一个工厂函数,这个工厂函数会读取环境变量和配置,决定当前该用哪个 provider,然后构建对应的 client 。
构建完成后,callModel() 和其他调用方都只会把它当成一个通用 Anthropic client。
这里很像工厂模式 + 适配器模式。
工厂模式解决的是启动时到底创建哪个 Provider。
适配器模式解决的是 Client 创建出来以后,外层用同一套接口调用它。
除此之外,callModel() 在选择调用方的时候,其实还用了策略模式。
不过,Query Loop 不关心你走的是 Direct API 还是 Bedrock,Provider 选择在启动时完成,直接将结果存进 STATE。
后面的 Agent Loop、工具系统、权限系统,都不会管 provider 是啥,职责分离。
构建系统
这一节讲构建系统。
Claude Code 既是 Anthropic 内部工具,也是公开的 npm 包。
这俩使用同一套代码库,然后通过编译时特性标志来控制包含哪些内容。
const module = feature("SOME_FLAG")
? require("./some/internal/module")
: null
这里的 feature() 来自 bun:bundle,也就是 Bun 的内置打包 API。
在构建时,每个 feature flag 会被解析成布尔字面量。
如果 flag 是 false,打包器会把对应 require() 整段删掉。
移除之后,模块不会加载,不会进 bundle,也不会发布。
也就是说 Claude Code 不是简单靠运行时判断来隐藏内部功能,它是在构建期就把某些路径裁掉。
但讽刺的地方就在这儿了。
早期 npm 包发布出来的 source map 里带了 sourcesContent。
这个字段包含原始 TypeScript 源码。
也就是说,feature flags 确实把运行时代码裁掉了,但是 source map 还保留着源码内容。
这直接导致了 Claude Code 源码被扒出来。
这些组件怎么连起来
所以回到刚开始看到的六个组件,这六个组件具有密切的关联关系。
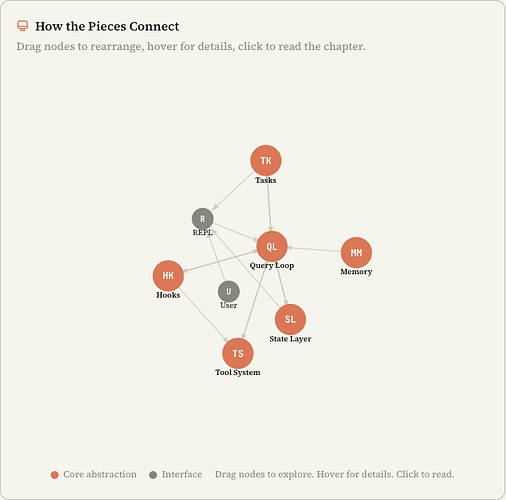
Memory 会作为系统提示词的一部分喂给 Query Loop。
Query Loop 驱动工具执行。
工具结果再作为消息回到 Query Loop。
Tasks 是递归的 Query Loop,只是有隔离的上下文。
Hooks 会在定义好的位置拦截 Query Loop。
State 被所有模块读写,同时响应设计会实时订阅 UI 状态。
Query Loop 和 Tool System 之间的循环依赖,是这个系统最核心的特征。
直到模型不再生成工具调用,或者 token 预算、最大轮次到了、用户取消之类的外部约束把它终止为止。
这就是 Agent 的本质。
所以现在可以回答正文开头哪句 Claude Code 到底是什么的问题了。
它是一个跑在终端里的 Agent runtime。
模型只是大脑。
工具是手脚。
权限是刹车系统
状态是神经系统。
Memory 是长期经验。
Hooks 是工程纪律。
Query Loop 才是心跳。
所以。。。你觉得它是什么?
后续章节我会沿着一次 Claude Code 的完整请求来展开,为大家介绍。
所以第一章算是提纲挈领性质的内容。
下一篇我会启动第二章:启动流程。
参考资料:
- Claude Code from Source, Chapter 1: The Architecture of an AI Agent
Ch 1. The Architecture of an AI Agent | Claude Code from Source
- Claude Code from Source 首页
https://claude-code-from-source.com/
- Anthropic Claude Code Docs: Overview
Overview - Claude Code Docs
 cxuan 楼主 06-29 09:371楼
cxuan 楼主 06-29 09:371楼 neverthink 06-29 09:402楼
neverthink 06-29 09:402楼 Copilot 06-29 09:434楼
Copilot 06-29 09:434楼 1A7432 06-29 09:467楼
1A7432 06-29 09:467楼 RayLee579 06-29 09:478楼
RayLee579 06-29 09:478楼 Aifire 06-29 09:479楼
Aifire 06-29 09:479楼 陈小爬 06-29 09:4910楼
陈小爬 06-29 09:4910楼 wannaX 06-29 09:5212楼
wannaX 06-29 09:5212楼 Cita 06-29 09:5613楼
Cita 06-29 09:5613楼 灵箓 06-29 09:5714楼
灵箓 06-29 09:5714楼 topwangyf 06-29 09:5916楼
topwangyf 06-29 09:5916楼 opps_xm 06-29 09:5917楼
opps_xm 06-29 09:5917楼